在人工智能的众多发展方向中,强化学习(Reinforcement Learning,简称RL)以其通过试错和环境反馈不断优化策略的独特机制,成为近年来备受关注的研究热点。强化学习的应用从游戏智能不断扩展到机器人控制、自然语言处理等领域,尤其是在线强化学习,由于其在新任务上的优秀适应性和知识保留能力,展现出远超传统有监督微调方法的潜力。本文聚焦于近期学术界提出的"RL's Razor"原则,即"RL的理性选择",深入探讨为何在线强化学习在面对新任务时遗忘旧知识更少,并结合理论分析与实际实验数据,为读者揭示这一现象背后的本质机理。 首先需明确所谓的"遗忘"问题。在机器学习中,尤其是当模型需要从旧任务迁移到新任务时,常出现所谓的灾难性遗忘,即模型在适应新任务的过程中,原有能力和知识迅速衰减或丧失。这一问题在传统的有监督微调(Supervised Fine-Tuning,SFT)中尤为明显,因为微调阶段的损失函数直接推动模型参数远离初始状态以适应新任务特征,往往导致与基模型的策略分布产生较大差异。
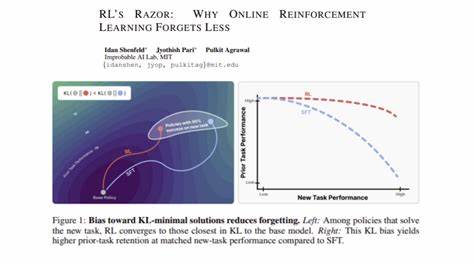
相比之下,最近发表的研究《RL's Razor: Why Online Reinforcement Learning Forgets Less》揭示了在线强化学习天然具备"KL散度约束"的隐性偏好,这种偏好促使模型在解决新任务时,更倾向于选择距离原始策略概率分布较近的方案。KL散度(Kullback-Leibler Divergence)是衡量两个概率分布差异的重要指标,在这一定义下,其数值越小表示两个策略分布越相似。强化学习中的这一特性意味着,策略更新虽持续适应新任务,但不会偏离基模型策略太远,从而显著降低遗忘程度。 研究团队通过对大型语言模型和机器人基础模型的多项实验进行了验证。实验结果显示,无论是在自然语言处理任务中还是在复杂控制任务中,经过在线强化学习调优的模型不仅能够在新环境中保持优异表现,同时对原有任务的掌握能力损失极小。这一结果与单纯采用监督微调的模型形成鲜明对比,后者在新任务同样达到相似性能时,却表现出明显的能力遗忘。
理论层面,此现象可通过强化学习的目标函数设计来解释。在一般的在线RL算法中,策略迭代被设计为最大化期望回报且附带一个小幅度的KL散度惩罚项,这样的约束确保策略更新过程中的变化在"合理范围"内,从而避免出现策略急剧偏离原基模型的情况。该惩罚项的存在不仅提升了训练稳定性,同时保证了模型在处理多样任务时的连续性和鲁棒性。 此外,从分布式视角来看,RL算法所采用的采样机制和策略更新规则使其更加关注在当前策略附近的探索,而非全局范围内的激烈跳跃。这种局部连续性优化路径的采择,进一步强化了模型遗忘较少的特性,也为在线学习带来了更高的效率和可靠性。 值得注意的是,虽然"RL's Razor"原则提出了强化学习中KL散度最小化的隐性偏好,实际应用中也应根据具体任务和环境调整该约束的强度和策略更新频率。
过强的KL约束可能导致学习过程过于保守,难以充分适应新任务复杂多变的需求,反之则可能削弱抗遗忘优势。因而,平衡策略更新的探索和保守性成为未来研究的关键挑战之一。 当前,随着大型语言模型和机器人系统在工业界和学术界的广泛部署,提升模型适应性和记忆能力显得尤为重要。RL's Razor为实现这一目标提供了崭新的理论视角和实践路径。通过利用强化学习的天然KL约束机制,不仅能够有效缓解灾难性遗忘问题,更能促进模型在多任务场景下实现稳定、连续的演进与优化。 总之,在线强化学习凭借其独特的策略更新机制,显著降低了在新任务学习过程中的知识遗忘风险。
RL's Razor为我们揭示了这种优势的根本所在,即策略演进通常会优先选择与旧策略分布相近的解决方案,从而保障了模型的连续性和稳定性。这一发现不仅深化了我们对强化学习内部工作原理的理解,更为未来构建更智能、更持久学习系统奠定了坚实基础。在实际应用中,结合RL's Razor原则调整策略更新方法,有望推动人工智能技术迈向更智慧、更可靠的新时代。 。









