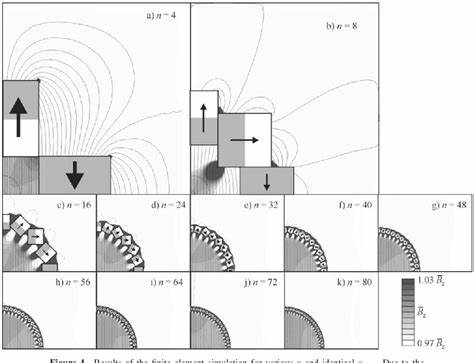
随着数据规模的持续增长和应用场景的不断复杂化,数据库技术面临着更高的性能和可靠性要求。KV_log作为一款高性能的嵌入式键值数据库,通过创新的hash-table树索引结构和日志追加存储机制,赢得了广泛关注和认可。它不仅专注于提升写入和读取的效率,还在数据一致性和系统稳定性方面做出了显著贡献。本文将详细解析KV_log的设计理念、核心架构及其在实际使用中的表现,帮助读者全面了解这款数据库的技术亮点和应用价值。 KV_log的整体设计基于高效的数据结构与存储策略。与传统数据库采用B树或LSM树索引不同,KV_log使用hash-table树作为索引结构。
该结构结合了hash table的O(1)平均查询复杂度和树形结构的层级组织,能够在海量数据中快速定位目标键值对。具体来说,KV_log内置一个主hash表,若多个键共享同一槽位置,则引入不同的salt值生成新hash表进行二次分布,形成层级索引树。这种设计有效减少了访问过程中磁盘页面的加载数量,从而大幅提升了读操作的响应速度。 在存储层面,KV_log采用日志追加模式确保写入的高效性和数据可靠性。数据以append-only方式顺序写入主文件,避免了随机写入带来的磁盘寻道延迟,极大提高了写入吞吐。与此同时,数据库维护一个写前日志(WAL)以保障在断电或崩溃时能够安全恢复。
WAL中保存已刷新的索引页信息,确保索引结构不会因异常中断而损坏。通过合理配置写模式,用户可以根据需求在性能与持久性中灵活权衡,从极限写入性能到全面保障数据安全均有覆盖。 KV_log的内部缓存机制也值得关注。为减少频繁磁盘I/O操作,对数据页实行智能缓存管理。缓存大小可根据实际硬件资源和业务负载配置,较大的缓存有助于提升读取性能,却会带来一定内存开销。系统同时监控脏页数量,触发合理的落盘时机,防止数据长时间滞留内存而丢失。
整体架构支持多线程并发读写操作,利用合适的锁机制确保线程安全和数据一致性。 该数据库对事务处理也提供支持,遵循ACID原则保证操作的原子性和持久性。开发者可以开启事务批量执行多个写操作,再选择提交或回滚,最大限度降低数据异常风险。同时,迭代功能允许遍历所有键值对,尽管数据不保证有序,但满足大部分扫描和数据分析需求。 在性能表现方面,KV_log显示出明显优势。权威测试中,其在写入200万条记录的速度远超行业内诸多知名产品,如BadgerDB和LevelDB。
读操作速度同样优秀,即使在冷启动状态下,仍保持了良好访问速度。与LMDB比较,KV_log虽然在读取速度上略逊一筹,但在写入性能和空间利用率方面占据明显优势。此外,KV_log的存储空间使用效率值得肯定,采取合理压缩和索引布局后,有效节约磁盘空间,降低了存储成本。 KV_log所限于单文件写入的设计限制,导致同一时刻仅允许一个写入进程,这对于分布式或者高并发写入场景存在一定挑战。但在多数嵌入式或单机应用环境下,这种设计反而简化了并发控制逻辑,降低复杂性,提高响应速度。多读单写模型确保多个线程或进程能够安全地并发读取,满足多数应用的读多写少模式需求。
对于应用开发者而言,KV_log提供了简洁易用的接口。常见的基本操作包括打开数据库文件、设置键值对、获取数据,删除操作简单明了,错误处理机制完备。事务操作接口支持多条数据的批量操作,在保证一致性的同时提升了应用层的控制灵活性。开发者还可选用丰富的配置参数,比如只读模式、缓存大小、脏页阈值和检查点触发条件,轻松适配自身业务需求和资源限制。 KV_log的开源性质和基于Apache 2.0协议的授权,使其更具吸引力。开发者和企业可以自由使用和二次开发,进一步优化性能或集成到特定系统中。
其代码完全使用Go语言编写,兼具跨平台能力和现代软件生态优势。对于寻求低延迟、高并发读写并且要求嵌入式部署的项目,KV_log无疑是值得考虑的重要选项。 总结而言,KV_log通过创新的hash-table树索引和高效日志追加存储方案,成为一款性能优越、功能全面的嵌入式键值数据库。它在读写效率、数据持久化和系统一致性之间实现了优良的平衡,适合于需要快速存取和高可靠性的场景。虽然存在单写进程限制,但对多数应用而言足够实用。随着技术迭代及社区贡献,KV_log有望继续优化其性能表现和扩展能力。
面对日益增长的海量数据处理需求,选择一款稳定可靠且高效的嵌入式键值存储工具,将为项目成功提供坚实基础。KV_log凭借自身独特架构和良好性能表现,正逐渐成为业界关注的焦点,值得开发者深入研究和广泛采用。