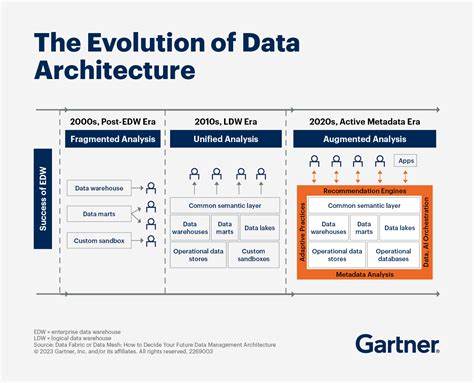
随着信息技术的迅猛发展,数据库架构及数据管理领域经历了深刻的变革。这些变革不仅反映了技术自身的进步,也体现了企业在处理海量数据、提升数据分析能力、优化系统性能等方面的不断需求。回顾过去几十年的发展轨迹,我们可以清晰地看到数据库技术如何不断适应业务场景的变化,从而推动现代数据管理体系的演进。 早期的数据库主要以关系型数据库管理系统(RDBMS)为主导。上世纪八九十年代,以甲骨文(Oracle V2)和IBM DB2为代表的关系型数据库系统成为企业处理事务数据和分析数据的核心工具。彼时,数据库主要采用单一系统完成在线事务处理(OLTP)以及在线分析处理(OLAP)工作。
在计算资源有限且数据量较小时,这种“一体化”数据库得到广泛应用。但随着数据规模的日益增长和业务需求的复杂化,传统关系型数据库面临性能瓶颈。事务和分析两种工作负载的资源利用冲突促使业界开始探索更为专业化的解决方案。 进入二十一世纪中期,NoSQL数据库的兴起标志着数据库架构进入了一个新阶段。由互联网巨头推动的NoSQL运动,以其分布式存储、弹性扩展和灵活schema优势,为处理海量非结构化数据提供了有效解决方案。这些数据库通常牺牲了严格的ACID特性,选择最终一致性模型,从而实现了高可用性和高扩展性。
MongoDB、Cassandra及DynamoDB等数据库成为支撑现代社交媒体、电商和云计算服务的关键基础设施。然而,NoSQL数据库的挑战也随之而来,如数据一致性的复杂管理、查询能力的限制及运维难度的增加。 同时,分析生态系统也经历了巨变。Hadoop及其分布式计算框架(如MapReduce和Apache Spark)将海量数据处理能力扩展至廉价的商用硬件上,极大地降低了大规模数据分析的门槛。分布式文件系统(如HDFS)的引入,为数据湖概念奠定了基础,使得结构化和非结构化数据能够以低成本、高弹性的方式进行存储和管理。但这些系统的复杂度及性能成本也促使业界探索更加高效的架构。
2014年,混合事务/分析处理(HTAP)概念应运而生,融合了OLTP和OLAP于一体,承诺能够消除传统数据仓库中的ETL瓶颈,实现实时数据分析。SingleStore(前MemSQL)和TiDB等HTAP系统尝试采用多引擎架构,将行存储的高性能写入和列存储的高效分析相结合。然而,HTAP的愿景并未完全兑现,受到运维风险、扩展性需求、云存储成本和组织架构等多方面的限制,许多企业仍选择分离的事务系统和分析平台。 值得注意的是,写前日志(Write-Ahead Log,WAL)的不断演进为数据同步和变更数据捕获(CDC)提供了极佳的基础。通过监听数据库的WAL,系统能够近实时地捕获数据变动事件并推送至分析引擎或流处理平台。Debezium、Apache Kafka等工具的出现,使得数据库操作和分析体系之间的耦合大幅降低,确保数据分析的时效性和系统的稳定性。
与此同时,数据湖仓(Data Lakehouse)架构成为业界新的焦点。结合了传统数据仓库的管理特性和数据湖的灵活性优势,数据湖仓利用Apache Iceberg、Delta Lake和Apache Hudi等开源表格格式,实现了ACID事务支持、时间旅行、模式演进及隐藏分区等功能。这些技术优势让企业能够在开放且弹性的存储层上构建统一的数据平台。 在数据处理平台上,曾经主导市场的Apache Spark因其复杂性和资源开销逐渐被专用查询引擎所替代。DuckDB凭借优异的单机性能和低成本的分析能力,成为小至中型分析负载的首选。Polars以其高效的内存管理和数据框架处理性能,获得数据工程领域青睐。
StarRocks和ClickHouse则在实时分析领域展示了强大实力,前者优化了大规模并发和复杂关联查询,后者在时序数据和日志分析中表现卓越。Trino作为分布式联邦查询引擎,实现了跨多数据源的统一查询,满足了各类异构数据集成需求。 在数据库技术层面,PostgreSQL凭借其强大的扩展性和合规的SQL标准,成为新兴事务系统的核心。通过集成如PostGIS、TimescaleDB及Pgvector等扩展,PostgreSQL不仅支撑传统事务,还日益适应地理空间、时间序列和AI向量数据的需求。Neon作为基于PostgreSQL的无服务器数据库,创新地实现了存储计算分离和时间点恢复等功能;Crunchy Data则通过集成DuckDB和Iceberg,为PostgreSQL加入了分析层能力,打造复合型数据库架构。 Databricks和Snowflake作为领先的云数据平台,尝试向HTAP发展,然而他们在事务处理方面遇到了架构实务上的种种限制。
Databricks基于Spark的批处理架构难以处理高频高并发的单行数据更新,Snowflake的微分区和计算模型也不适合低延迟事务处理。两家公司纷纷通过收购Neon和Crunchy Data,强化PostgreSQL能力,推动事务与分析架构的协同发展,显示出未来数据管理将更加注重多引擎组成的生态。 ClickHouse的飞速发展和巨额融资凸显了其专注分析场景的独特定位。拒绝杂揉HTAP的复杂尝试,ClickHouse通过深入优化的列存储结构、向量化查询执行以及高效索引设计,实现了在日志分析和时序数据库领域无可匹敌的性能优势。它不仅兼容数据湖仓的表格格式,也能与流式平台无缝衔接,体现了现代数据架构强调组件协同而非一体化的趋势。 微软Azure生态的策略则更多体现了市场跟随性质。
其数据湖存储、Synapse分析服务、流处理及Fabric品牌均为借鉴业界成功经验的产物,具备良好的云原生集成度,但相较领先企业在性能和功能创新方面稍显滞后。作为云服务商,Azure在整合自身生态的同时,仍需在核心数据管理创新上持续发力以巩固市场份额。 面向未来,政府及企业系统的数据库和数据管理策略应秉持稳健且灵活原则。继续采用成熟的关系型数据库(如Azure SQL和PostgreSQL)作为关键业务的事务存储,逐步推进数据湖仓架构以应对非结构化和大规模数据。优先选择Apache Iceberg作为开放式表格格式,保证数据一致性和灵活治理。数据管道方面,视任务复杂度选择合适技术栈:简单ETL可采用Azure Functions结合C#、TypeScript,复杂数据处理引入Python及Polars,而真正超大规模计算则交由Spark/Databricks处理。
变更数据捕获机制应标准化建立,确保数据在各系统间的实时同步,降低对业务系统的影响。查询引擎选型需依据具体场景:DuckDB适合小规模即席分析,StarRocks满足实时高并发需求,ClickHouse优化时序与日志分析,Trino适合跨源数据联邦查询,Spark则服务于极大规模机器学习及数据科学任务。借助Apache Arrow作为内存交换标准及Hive Metastore统一元数据管理,实现多引擎间高效协同和数据互操作,最大化资源利用率。 总体来看,数据库架构的演变不仅是技术的迭代,更反映了业务对数据价值挖掘的不断深化。未来数据管理将以开放、模块化、协同为核心,专用引擎与通用平台形成共生共赢的生态。深刻理解这些发展趋势和技术选型,将助力企业打造高效、可扩展、智能化的数据驱动系统,迎接数字经济新时代的挑战与机遇。
。