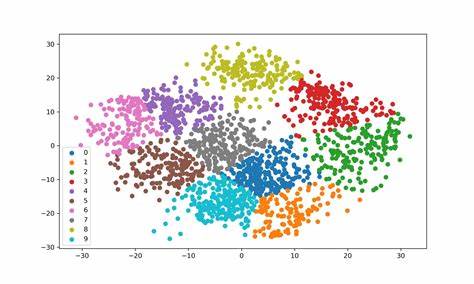
随着大数据时代的到来,数据聚类作为数据分析的重要技术之一,受到了广泛关注。在众多聚类算法中,K-Means因其简单高效和易于实现成为主流选择。然而,传统的K-Means算法在处理大规模和高维数据时,常常面临性能瓶颈和资源消耗问题。针对这一挑战,Kentro作为一款基于Rust语言开发的高性能K-Means聚类库应运而生,为聚类算法的快速执行和功能多样化带来了新的选择。Kentro不仅实现了标准K-Means算法,还涵盖了多种算法变体,包括球面K-Means、平衡K-Means以及K-Medoids算法,极大地丰富了用户的聚类方案选择。Rust语言作为其开发基础,为Kentro提供了高效的内存管理和并行计算能力,使其在处理海量数据时表现出色。
标准K-Means算法借助Kentro的实现采用了经典的Lloyd算法,在准确性和速度之间取得了良好平衡。球面K-Means则使用余弦相似度作为距离度量,特别适合文本聚类和高维数据的分析;这种方法通过度量向量的方向相似性,有效捕获语义关系。平衡K-Means功能使得聚类结果更加均衡,避免了部分簇规模不均带来的偏差问题,其核心算法基于最新的高效平衡策略,适合需要簇大小约等的场景。K-Medoids算法通过选择实际数据点作为簇中心,增加了对异常值的鲁棒性,有助于实现更具解释性的聚类结果,特别适用于噪声较多的数据集。Kentro在性能优化方面做出了显著贡献。它利用Rust的强类型系统和零成本抽象优势,结合并行计算框架Rayon,实现了多线程的并行聚类过程。
用户可以灵活控制线程数,从单核到多核CPU均可高效利用,显著减少计算时间。此外,Kentro采用ndarray库进行矩阵运算,保证了内存使用的高效和数据访问的快速,适合处理大规模的高维数据。API设计方面,Kentro采用建造者模式,用户可以通过链式调用配置聚类参数,如簇数量、迭代次数、是否启用平衡聚类、使用何种距离度量以及是否启用K-Medoids。这种灵活设计降低了使用门槛,同时便于集成到复杂项目中。Kentro还针对Python用户提供了完善的绑定接口,支持NumPy数组作为输入,使得Python开发者无需脱离熟悉的生态系统即可调用Rust实现的高性能聚类算法。这极大地方便了跨语言协作和快速原型开发。
错误处理机制是Kentro的另一大亮点。它通过细致的错误类型覆盖了如数据点数量不足、已训练模型重复训练等常见问题,提升了代码的健壮性和调试体验。针对用户的不同需求,Kentro还提供了训练好的模型状态查询、簇中心和代表点的获取接口,方便后续数据分析和模型应用。在实际应用场景中,Kentro适用于文本聚类、图像分割、客户分群、异常检测等众多领域。球面K-Means在文本挖掘中对TF-IDF特征的处理尤为出彩,有效分离主题,实现精准的文档分类;平衡K-Means则被广泛应用于电商用户画像,确保各用户群体均衡划分,有助于精准营销。K-Medoids的鲁棒性适合金融风控领域,对于异常交易模式识别效果优秀。
此外,Kentro的并行计算优势使得它非常适合嵌入到大数据处理流水线中,支持实时或近实时的聚类分析。其低内存占用和高效计算能力,为云端和边缘计算环境提供了广阔的应用前景。作为开源项目,Kentro在Github平台上积极维护,拥有完善的文档和示例代码,包括基础聚类、平衡聚类、K-Medoids以及Python绑定的实战案例,为用户快速上手提供有力支持。它还集成了全面的测试机制,确保功能稳定和性能优异。未来,Kentro计划进一步扩展支持更多聚类算法变体和自动化参数调优功能,提升易用性和智能化水平。同时将持续优化多语言绑定,促进多样化生态系统的融合。
总的来说,Kentro作为一款利用Rust语言优势打造的K-Means聚类库,不仅性能极为出色,还兼具灵活的算法选择和友好的开发接口。它满足了现代数据分析中对速度、准确性和稳定性的多重需求,是科研人员和工程师实现高效聚类分析的理想工具。选择Kentro,意味着选择了一条走向高性能和实用性的智能聚类之路。