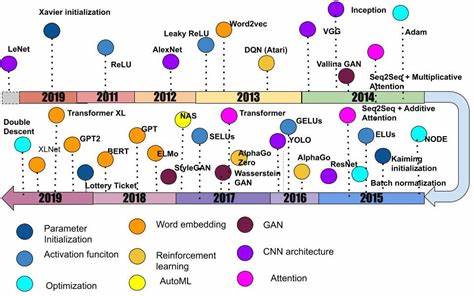
2010年代是深度学习领域的黄金十年,这十年间,人工智能技术以前所未有的速度发展,深刻改变了我们对计算机视觉、自然语言处理、强化学习及生成模型的理解和应用。随着计算能力的快速提升和海量数据的涌现,深度神经网络从理论研究走向实际应用,开启了人工智能新时代。 早在2010年,研究人员就开始聚焦于神经网络的权重初始化问题,解决了梯度消失和梯度爆炸等训练障碍。Xavier初始化方法的提出,标志着深度神经网络训练技术的进步,为后续更深层网络的设计铺平了道路。随后2011年,ReLU激活函数被广泛推广,凭借其简单高效的特性有效缓解了传统Sigmoid激活函数存在的梯度衰减问题,为构建更深层、更复杂的神经网络架构提供了技术保障。 2012年的里程碑式工作——AlexNet的出现,则正式引爆了深度学习的新浪潮。
该网络借助GPU计算,实现了八层卷积神经网络的成功训练,在ImageNet竞赛中大幅降低错误率,引发了全球范围内对深度卷积网络的热情探索。AlexNet不仅证明了深度学习的巨大潜力,也推动了大规模标注数据集的建设,ImageNet数据库的成功让学术界和工业界得以共同参与计算机视觉技术的持续迭代进步。 紧接着,2013年word2vec模型的发布,为自然语言处理领域带来了革命。word2vec通过分布式向量表示捕捉词汇间的语义和上下文关系,使得文本处理任务取得了突破性的进展。至此,自然语言处理开始从符号处理走向深度表示学习。与此同时,强化学习领域也迎来重大突破,DeepMind成功应用深度Q网络(DQN)在高维视觉输入的Atari游戏中取得突出成绩,将深度学习与强化学习有机结合,催生了深度强化学习的繁荣。
2014年见证了生成模型的巨大创新,生成对抗网络(GAN)的诞生带来了图像生成的全新范式。通过引入生成器与判别器之间的博弈对抗机制,GAN能够逼真地模拟复杂数据分布,迅速成为视觉生成任务的核心技术。不同于传统生成模型,GAN具备自主学习生成样本的能力,应用扩展至图像修复、风格迁移、甚至音频和文本生成领域。为解决训练不稳定和模式崩溃问题,后续出现的Wasserstein GAN等变种极大提升了训练质量和效果。 不仅如此,注意力机制的引入使得模型能够聚焦于输入序列中最关键的部分。2014年提出的基于注意力的神经机器翻译架构,摆脱了传统RNN编码器-解码器的瓶颈,为语言模型输入信息的灵活处理奠定基础。
紧随其后,2017年《Attention Is All You Need》论文发表,Transformer架构掀起了自然语言处理领域的革命。基于自注意力机制的Transformer模型废除了循环结构,实现高度并行计算,从而显著提升了训练效率和建模能力。如今,Transformer已成为众多语言理解和生成模型的核心,包括BERT、GPT系列等,推动自然语言处理迈入大规模预训练时代。 2015年后,深度残差网络(ResNet)的提出解决了超深层网络训练的技术难题。通过引入跳跃连接机制,ResNet有效缓解了梯度消失,保证了深层模型的性能提升。其简洁而高效的结构设计,成为计算机视觉领域诸多模型的基石。
与此同时,Batch Normalization技术的广泛应用,稳定了训练过程,缩短了训练时间,为构建复杂网络架构提供坚实保障。 在强化学习领域,2016年AlphaGo的惊艳亮相突破传统棋类AI的能力上限。结合深度神经网络与蒙特卡洛树搜索策略,AlphaGo系统不仅击败了世界顶级围棋高手,也展示了深度学习在高难度策略决策中的潜力,深远影响了人工智能与游戏竞技的融合方向。此后,AlphaGo Zero进一步实现了完全自我博弈驱动的端到端强化学习,超越了人为先验知识,开创了新型无监督学习范式。 除了上述领域,优化算法的进步也不可忽视。Adam优化器因其自适应调整步长的优势,成为主流训练算法之一。
尽管存在争议,Adam依然是很多神经网络训练的默认选择。同时,神经网络架构的自动搜索(NAS)方法兴起,借助强化学习或进化策略自动生成高效网络结构,极大节省了人工设计的成本,进一步推动模型性能提升。 2018年深度学习在自然语言处理领域再次实现质的飞跃。BERT模型提出了双向编码表示,通过Masked Language Model任务让模型能从全方位理解上下文含义,这一创新显著提升了多项自然语言理解任务的性能,同时促进了大规模预训练与微调范式的普及。此后GPT-2的发布再次震动业界,其生成语句的流畅和多样性为空前,激发了生成式语言模型的研究热潮。 2019年,研究者开始关注深度学习的理论基础和泛化能力,特别是“深度双重下降”现象被提出,颠覆了传统的偏差-方差权衡理论,揭示了过大模型在某些情况下依然可以实现良好泛化能力。
此外,“彩票假说”探讨了大型神经网络内部存在可有效训练的稀疏子网络,提示模型大小优势背后隐藏着幸运的初始化因子,为网络剪枝和高效训练提供了新的理念。 回顾过去十年,深度学习的爆炸式发展不仅源于创新算法和模型结构,更得益于硬件计算能力的持续提升和数据集的规模化建设。深度神经网络已经广泛渗透于自动驾驶、医疗影像、语音识别、机器翻译等多个领域,产生深远社会影响。 然而,深度学习也面临诸多挑战,如对大量标注数据依赖、模型可解释性不足及跨任务泛化能力有限等问题,引发了业界的深入反思。未来的研究趋势可能更加注重融合深度学习与符号推理、开发更高效的自监督和无监督学习算法,并强化对网络训练动态及泛化机理的理论理解. 展望未来,人工智能领域将在深度学习基础上迈向更高层次的智能化。跨模态学习、自动机器学习(AutoML)、强化学习与生成模型结合、自适应与终身学习等方向,有望成为2020年代科技探索的重点。
深度学习作为人工智能发展道路上的基石,将继续推动技术创新和应用变革,带领我们不断向实现通用人工智能目标迈进。 深度学习的十年历程是一段从实验室走向千家万户的壮丽史诗。得益于开放共享的精神与跨领域的协作,全球科研人员共同编织了这场智慧革命的篇章。在新十年的征程中,继续保持创新热情与理论探索,将使我们更接近人类智能的真正本质。拥抱深度学习的未来,未来的智能社会已经向我们招手。