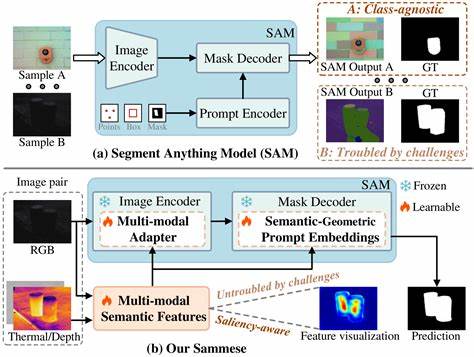
随着人工智能和计算机视觉技术的飞速发展,图像分割技术作为视觉理解的重要环节,越来越受到研究者和行业的关注。Semantic-Segment-Anything(简称SSA)作为一项创新的图像分割技术,通过为Segment Anything模型赋予语义标签,极大地提升了视觉识别的细粒度能力,成为图像分割领域的热门研究方向。SSA不仅填补了传统Segment Anything数据集在细粒度语义标签上的不足,还通过自动化标注显著降低了人工成本,为未来的大规模视觉感知模型训练奠定了坚实基础。Semantic-Segment-Anything的核心价值在于其对Segment Anything模型的数据集SA-1B的扩展和升级。原始的SA-1B数据集以大量图像掩码为核心,关注的是图像区域的准确分割,但缺乏丰富的语义信息,难以满足复杂视觉任务对类别识别的需求。而SSA利用其智能注释引擎为每一个分割掩码添加了类别名称和类别建议,这些语义标签使得图像分割不仅停留在像素层面,更深入到语义理解层面,为后续图像分析和应用提供了坚实的数据基础。
SSA引擎的设计理念独具匠心,它融合了密闭集语义分割与开放词汇分类的优势,从而实现了更精准且多样化的语义标注。引擎包含三个核心模块。首先是密闭集语义分割器,它基于COCO和ADE20K这两个广泛使用的语义分割数据集训练,能提供基础且准确的语义类别,保证每个分割掩码初步获得可信的标签。随后,开放词汇分类器通过图像描述模型的辅助,将掩码对应图像区域的描述转换成名词或短语,生成丰富的类别候选列表,这一步极大地扩展了语义标签的覆盖范围,允许识别更为细致的对象和场景。最后,决策模块利用CLIP类模型筛选最佳类别组合,通过对候选类别与图像区域的综合评估,最终确定最合适的标签,进一步增强语义分割的准确性和表现力。这一流畅的三阶段机制,使SSA在保证基础标签准确的同时,兼顾了多样性和开放性,满足了现实视觉场景中多变且复杂的语义需求。
SSA不仅在技术架构上展现出独特优势,在实际应用中同样表现卓越。依托强大的NVIDIA A100 GPU硬件支持,SSA能够在大约25秒内完成一次预测,效率与精度兼备,适合多样化图像输入条件。其自动化注释过程大幅降低了对人工标注的依赖,有效节约成本与时间,特别适用于大规模数据集的快速语义标注需求。对于企业及研究者来说,SSA提供了公开源代码和Docker部署方式,方便用户根据自身需求灵活部署和扩展,兼容性高且操作门槛低,增强了技术推广和二次开发的可能性。此外,该模型在Replicate平台上公开运行,成本合理,为开发者提供低门槛的试用途径。Semantic-Segment-Anything在促进大规模视觉感知模型发展方面具有深远意义。
随着智能应用对细粒度视觉理解需求的不断提升,SSA丰富的语义标签为训练更强大的视觉模型提供了关键支撑。在自动驾驶、智能监控、医学影像分析等多个领域,SSA的精细语义理解能力能够有效提升系统的识别准确率和响应速度,助力产业智能升级。未来,随着技术的不断迭代与完善,SSA有潜力融合更多先进的视觉和语言模型,实现更智慧的图像语义分割功能。尤其是在结合大规模预训练模型与多模态深度学习技术后,SSA或将实现对复杂视觉任务的自主学习和适应,开启视觉智能的新格局。Semantic-Segment-Anything的成功还得益于开放社区的发展与协作,借助HuggingFace、CLIPSeg、OneFormer、BLIP和CLIP等先进模型的支持,构建起一个多维度协同的视觉理解生态。这不仅加速了技术迭代,更推动了学术界和工业界的紧密合作,实现了理论与实践的良性循环。
综上所述,Semantic-Segment-Anything作为一款跨越基础分割与语义理解的创新工具,突破了传统图像分割技术的瓶颈。它通过自动化、高效且多元化的语义标签赋予,使得图像分割不仅停留于视觉分割本身,更具备深层次的语义洞察和智能判断能力。随着技术的普及和应用领域不断扩展,SSA必将在视觉智能领域扮演越来越重要的角色,驱动行业变革与科学进步。对于图像分割技术的研究者、开发者以及应用企业而言,深入理解与掌握SSA的原理与优势,将为未来创新之路提供强大助力和广阔空间。