近年来,人工智能领域中大型语言模型(LLMs)的迅猛发展极大地推动了自然语言处理技术的进步,但深度推理能力仍然是一大挑战。尽管链式思维(Chain-of-Thought, CoT)提示技术在一定程度上提升了模型处理复杂任务的能力,却依赖大量人工标注的推理示范,存在可扩展性和偏差问题。在此背景下,DeepSeek-R1以其独特的强化学习(Reinforcement Learning, RL)训练框架,成功突破了这些瓶颈,激发了大型语言模型自主进化复杂推理能力的新可能。DeepSeek-R1的出现可谓为智能推理领域注入了新的活力,其先进的训练方法和性能表现不仅刷新了数学、编程及理工科领域的大规模推理标准,更为未来人工智能模型的自主学习奠定了坚实基石。传统监督学习模式主要依赖人类专家标注的推理过程示范,这造成了扩展性受限和随之而来的认知偏见,从而限制了模型探索更优推理路径的空间。DeepSeek-R1通过引入纯强化学习的方法,取消了对人类标注推理轨迹的依赖,仅依照最终答案的准确性作为奖励信号,使得模型能够自由探索多样化、甚至超越人类思维的推理策略。
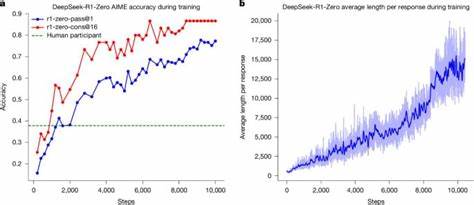
在这一过程中,DeepSeek-R1展现出了令人振奋的自我反思、自我验证及动态策略调整能力,从而极大地提高了其解决复杂问题的水平。DeepSeek-R1的训练基底是DeepSeek-V3 Base模型,通过采用群体相对策略优化(Group Relative Policy Optimization, GRPO)算法,构建起高效且可扩展的强化学习训练流程。在训练时,模型被设计以特定格式输出推理过程及最终答案,推理环节被标记为<think>标签包裹,答案部分以<answer>标签呈现。这种结构化设计不仅确保了推理过程的可解释性,也避免了内容上的偏置,推动模型真正从尝试错误中吸取经验。经过数千次训练迭代,DeepSeek-R1-Zero版本表现出从15.6%至77.9%的美国数学邀请赛(AIME)准确率提升,利用自洽解码策略可进一步达到86.7%,超过众多参赛人类选手。这组数据令人印象深刻地证明了纯强化学习可以有效激励LLM推理行为。
此外,DeepSeek-R1-Zero不仅在数学领域表现突出,也在代码竞赛和生命科学、物理、化学等研究生级别的理工学科问题上实现了卓越性能。伴随着推理能力的提升,模型的响应长度也明显增长,展现出逐步加长推理链条、自主反思与多角度验证的自我进化趋势。随着训练的深入,模型更频繁地使用如"wait"等反思词汇,表明其开始具备一定的元认知能力,能适时暂停、审视推理步骤中的不确定性或错误,体现了推理策略的进阶发展。DeepSeek-R1虽已在推理能力上大放异彩,但在语言混用、输出格式一致性及通用写作能力方面仍存改进空间。为此,研究团队设计了更完善的多阶段训练框架,融合拒绝采样(Rejection Sampling)、强化学习及监督微调(Supervised Fine-Tuning, SFT),形成了更趋完善的DeepSeek-R1模型。通过该训练流水线,模型在保留强大推理能力的同时,显著提高了语言一致性和人类喜好对齐度。
特别是在融合非推理数据、编程和写作任务后,DeepSeek-R1表现出更加丰富的语言生成能力,并在众多语言理解及指令跟随评测标准中获得明显提升。这种多任务混合训练也推动了模型更加平衡和稳健的表现。在奖励机制设计上,DeepSeek-R1采用了结合规则基础和模型基础的奖励体系。针对数学和代码类准确性强的任务,规则奖励确保了目标准确性和格式规范。而对于更为广泛且复杂的开放域问题,则通过训练有素的奖励模型捕获人类对回答有用性及安全性的偏好,综合提升模型在实际应用场景中的表现和安全性。深度分析显示,凭借GRPO算法有效权衡了提升策略多样性与防止策略过度变动之间的关系,使得训练过程既稳定又高效。
同时,模型的自我监督使其具备持续自我优化的潜能。与主流采用PPO算法的强化学习方案相比,GRPO简化了训练流程,减少了计算资源消耗,更适合大规模语言模型的强化训练。安全性方面,尽管提升了推理能力,DeepSeek-R1依然可能面临恶意使用风险,如更有效的绕过安全限制攻击。对此,团队进行了多维度安全检测,结果表明模型在未结合风险控制系统时能达到与市面先进模型GPT-4o相当的中等安全水平,配合风险控制策略后,则达到更为优秀的防护标准。此外,模型开放了不同规模版本的蒸馏模型,赋能研究社区更方便地探索长链推理机制和训练范式,为后续技术积累和创新奠定基础。展望未来,DeepSeek-R1仍有不少挑战需要克服。
其当前结构化输出能力仍不及专用结构化生成模型,集成搜索引擎、计算器等工具辅助推理尚未实现,这些都可能成为提升复杂任务表现的关键突破点。推理过程中的代币效率也有待进一步优化,避免在简单问题上出现不必要的过度推理。同时,语言混用问题需要针对不同语种训练得到强化,确保模型能在多语环境中表现均衡。推进大规模软件工程任务的强化学习训练亦是重要方向,未来或通过更优化的样本筛选和异步评估方法来提升训练效率。此外,纯强化学习受限于准确且难以构造奖励信号的任务仍有较大改进空间,如何设计更加鲁棒的奖励模型以防止"奖励劫持"现象,是后续研究的重要议题。DeepSeek-R1代表了使用强化学习激励LLMs推理能力的典范,它的成功证明了在给定具备严格验证机制的问题上,人工智能模型能通过自我探索实现超越传统方法的认知飞跃。
随着技术不断成熟,能够自适应、自进化的智能模型将逐渐成为现实,有望在科学研究、工程设计、教育辅导等多个领域发挥深远影响。DeepSeek-R1不仅是推动推理AI研究前沿的重要里程碑,更为智能机器的高度自主化与不断进化提供了范例和启示。未来的探索将聚焦于加强模型的工具能力、多语言适应性及复杂奖励设计,进一步扩大AI推理的使用场景,实现更智能、更安全、更高效的人机协作。 。









