在现代 Web 开发中,Node.js 由于其高效的异步处理能力和广泛的生态系统,成为了构建服务器端应用的重要选择。而 Express 作为 Node.js 最受欢迎的 Web 框架之一,简化了许多服务器开发中的复杂流程。在处理 HTTP 请求时,往往需要获取请求体(Body)中的数据,尤其是获取原始请求体内容,对于实现安全验证、内容校验或者处理非标准格式数据时尤为关键。本文将围绕如何在 Node.js 环境中利用 Express 框架有效获取原始请求体展开详细探讨,帮助开发者理解底层机制并掌握实用技巧。首先,需要明白 HTTP 请求体的数据载体通常是以 Buffer 或者字符串的形式存在。Express 中默认使用的中间件如 body-parser 或者内置的 express.json() 会对请求体进行解析,将其转换成 JavaScript 对象,直接使用 req.body 获取。
然而,这种解析在某些应用场景中可能不满足需求,比如进行消息摘要(如 HMAC 认证)、数字签名校验或处理非标准格式数据时,我们需要原封不动的请求体内容,也就是获取请求的"原始"数据。传统方法曾是通过监听请求对象的 data 事件和 end 事件,将分块的数据累积起来形成完整的请求体字符串或者 Buffer。示例代码通常包含对 req.on('data') 事件的监听,每当客户端传输数据块时,服务端将其保存,最后在 req.on('end') 事件触发时合成。尽管这个方式直观,但存在与现代中间件冲突的风险,因为数据流只能被消费一次,若提前消费会导致后续解析失败。随着 Node.js 与 Express 体系的发展,社区推出了更为优雅的方案。对于 Express 4 及以上版本,推荐使用独立的 body-parser 中间件,尤其其中的 raw 模式。
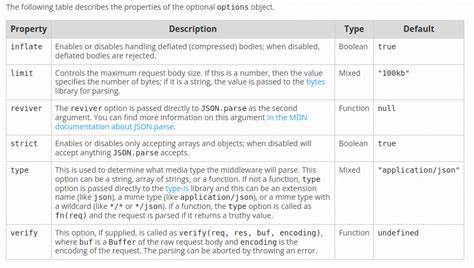
body-parser 的 raw 解析模式可以返回原始的 Buffer 对象,开发者可通过配置 type 属性来指定处理的 MIME 类型,例如 application/octet-stream。这种方式兼具对流完整的读取和方便的调用,且能与解压缩功能(gzip/deflate)配合,增强兼容性。值得关注的是,在使用 body-parser 时,可以利用它的 verify 选项,在解析时插入自定义逻辑。verify 函数在接收到请求体 buffer 后执行,允许开发者将原始数据保存到 req 对象的自定义属性中,比如 req.rawBody,这样既不破坏后续解析流程,也可以安全访问原始内容。这样做对于实现签名校验、日志监控等极具价值。例如,您可以在 app.use(bodyParser.json({ verify: rawBodySaver })) 中定义一个 rawBodySaver 函数,将 Buffer 转化为字符串后存储。
配置时还可兼容 urlencoded 和 raw 类型请求,满足不同业务需求。另一方面,对于处理特定 Content-Type 的文本数据,如 text/plain,也可以自行编写中间件,先判断请求头的类型,匹配成功后累积数据块,最后设置 req.rawBody。此法对维护应用稳定性具有一定优势,但需要谨慎处理数据流,避免与其它中间件产生冲突。在许多开发实践中,尤其是涉及第三方服务 Webhook 验证时,获取精确的原始请求体是必须的。举例来说,支付平台的通知回调通常要求验证内容完整且未被修改,通过保存请求体的原始 Buffer 版本,开发者可计算准确的 HMAC 或其他摘要值,提升安全防护等级。值得提醒的是,在设计应用中获取原始请求体时,不推荐同时在多个中间件中重复消费请求流。
务必确保数据流只被消费一次,选择合适的插入点和方法,避免出现请求挂起或响应延迟等问题。综合来看,当前获取原始请求体的最佳方案是配合 body-parser 的 verify 选项,既保证中间件的正常工作,又能灵活读取到未加工的请求内容。实践中,合理配置中间件类型与路径,明确请求数据格式,结合 encode 设置,将让开发者轻松应对复杂的请求解析需求。未来,随着 Node.js 不断迭代,可能会有更便捷的原生方案出现,但掌握现有成熟方法无疑是每位后端开发者的重要技能。通过本文的解析与示例,您已经具备使用 Express 获取原始请求体的核心能力,为构建更加安全、高效的服务端程序奠定坚实基础。 。