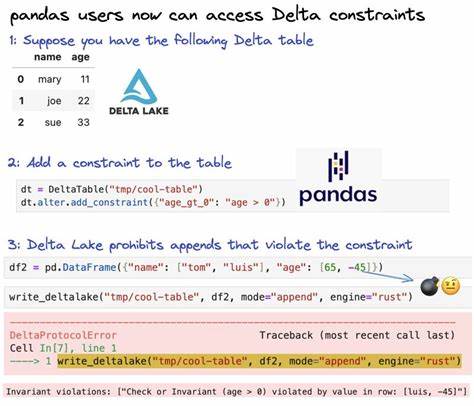
在现代数据科学领域,Pandas已经成为数据分析与原型构建的首选工具,其简单便捷的API和强大的数据处理能力让无数数据科学家得以迅速开发和验证数据模型。然而,随着项目规模扩大及生产环境对数据可靠性和一致性的更高要求,传统Pandas工作流所基于的文件格式和技术架构逐渐暴露出局限性。尤其在处理大规模数据、支持并发修改以及维护数据版本历史时,依靠普通的Parquet或CSV文件变得繁琐且难以管理。此时,Delta Lake作为一项创新技术进入了数据科学和数据工程的视野,它通过提供企业级数据湖功能,助力Pandas工作流从实验阶段顺利过渡到稳定的生产管线。Delta-rs,作为Delta Lake的Rust原生实现,使得Python环境下无需依赖繁重的Spark集群或JVM环境,即可享受ACID事务、时间旅行、模式演进等高级特性,极大地简化了生产级数据系统的构建门槛。Delta-rs的出现意味着数据科学家们可以更自由地利用Pandas的操作体验,同时获得数据一致性、并发控制与灵活架构演进的保障,兼顾效率与稳定性。
本文深度剖析了Delta-rs如何助力数据科学家利用NYC黄出租车数据构建生产级Delta表。演示从基础的数据加载与表构建,到高效的数据增量更新与CRUD操作,再到时间旅行查看历史版本,以及自动的模式演进和跨引擎支持,全面展示了Delta Lake在真实场景中的应用价值。通过Delta-rs进行数据写入时,采用覆盖(overwrite)或追加(append)模式均可保证数据的原子操作,避免了传统Parquet文件在更新时需要全量重写的低效问题。较之Pandas传统范式处理全部数据后写盘,Delta-rs智能处理新增或变更记录,显著提升了数据管线的性能和响应速度。时间旅行与版本控制功能同样让审计、回滚操作变得简单无忧。用户无需自行管理复杂的备份策略,只需通过指定表版本号即可访问任意历史状态,极大便利了数据治理和合规要求的实现。
模式演进功能则支持在数据表结构发生变更时自动合并新旧字段,允许平滑引入新业务字段而不破坏历史数据。对于需要围绕新增气象条件和价格浮动等字段扩展分析的场景尤为重要,避免了因手动迁移或硬编码维护所引发的管线中断。Delta-rs的合并(merge)操作进一步增强了数据更新的灵活性,支持基于匹配条件对指定记录进行精确的更新或插入,取代了传统方法中全表扫描、筛选与重写的繁琐过程。当数据量攀升时,节省的I/O和计算资源尤为可观,且保证了事务的一致性。多引擎整合能力体现了Delta Lake生态的开放与兼容。无论是习惯使用Pandas进行探索性分析,偏好DuckDB的高性能SQL查询,还是追求Polars极致速度的数据处理团队,都能够共同访问和操作同一套Delta数据,无需借助繁重的ETL转换或格式复制。
这大幅减少了数据孤岛和重复存储,提升了团队协作效率。Delta-rs还内置了自动垃圾回收(vacuum)功能,智能识别无用版本文件并安全删除,帮助控制数据湖存储空间增长,确保在保留必要的历史版本同时避免磁盘资源的浪费。对于生产环境中稳定运行和成本优化至关重要。总的来说,Delta Lake通过Delta-rs极大地降低了将Pandas原型转为生产数据管线的门槛,既保留了Pandas的数据分析优势,也满足了企业对数据仓库一致性、扩展性和管理性的高标准。它允许数据科学家摆脱传统文件系统的限制,以更高效、更可靠的方式构建面向未来的数据平台,为数据驱动的决策和产品创新提供坚实基础。未来,随着更多数据工程工具和框架围绕Delta标准展开,Python社区的开放生态将更加丰富多彩,数据科学、数据工程和AI研发的协同也将进入一个崭新的阶段。
。