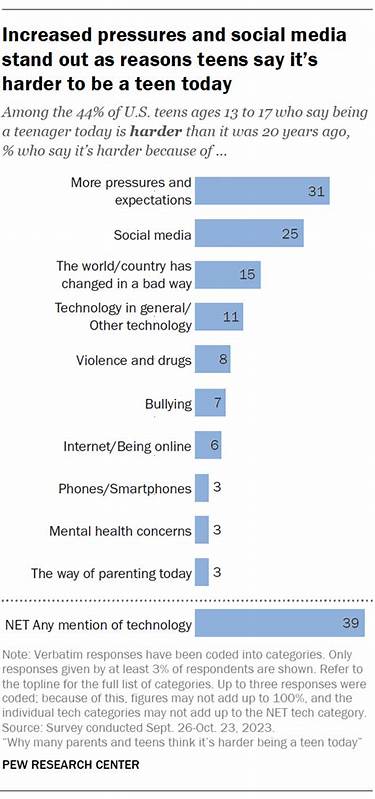
加拿大统计局(Statistics Canada)作为加拿大官方权威的统计数据发布机构,其提供的数据涵盖了社会、经济、地理及人口等多个领域,成为研究、政策制定和商业分析的重要基础。近日,数据科学家Diego Ripley完成了对加拿大统计局提供的所有数据表的完整处理与分析,共计7918个数据表,体量达到3314.57GB。这一规模庞大的数据处理项目,既揭示了现有数据发布机制的不足,也展现了通过技术优化带来的巨大潜力。本文将全方位剖析这一项目的实践过程、遇到的挑战、解决方案及未来发展方向,为广大数据分析师和地理信息系统用户提供宝贵参考。 加拿大统计局目前通过其Web数据服务(WDS)提供数据表下载,主要格式为CSV和XML,并以ZIP文件压缩发布。尽管资源丰富,下载和处理流程繁复,需要用户逐个获取文件并解压,造成效率低下和资源浪费。
Ripley选择了英文版的CSV文件进行处理,面对总计压缩178.33GB、解压后超过3TB的庞大数据量,他着手对数据结构进行优化,最终将转换后的Parquet文件整体压缩至25.73GB,仅占原始压缩包的14.43%。这一优化不仅节省存储空间,更大幅提升了数据读取和查询效率。 在数据处理过程中,Ripley针对数据表中的关键字段VALUE,采用根据数值规模精确划分的数据类型。例如,对于最大整数值低于32位整数上限的字段,决定采用32位整数存储,减少内存占用。这种精细的类型优化对大规模数据分析至关重要,能够显著降低硬件负担,加快数据处理速度。此外,针对时间参考字段REF_DATE,他增加了REF_START_DATE和REF_END_DATE两个新字段,将格式多样的日期数据统一转换为标准的日期范围,使得基于日期区间的查询操作得以高效实现,方便数据在SQL引擎或分析工具中的灵活应用。
尽管技术手段明显提升了数据使用便捷性,项目中也暴露了若干值得关注的数据质量和一致性问题。首先是时间戳(releaseTime)在不同接口中的时区不统一与时间差异问题。通过对两个API接口的对比测试,发现getAllCubesListLite接口返回的releaseTime为UTC时区,而getCubeMetadata接口返回的则为东部标准时间,这种不统一导致时间信息语义不清,影响数据同步和版本管理。此外,有部分数据表的releaseTime存在长达三年的差异,给数据的时效性判断带来极大困扰。 数据标识符productId的类型在不同接口之间也不一致,部分接口中以整数呈现,另一接口返回字符串格式,虽然对程序设计影响小,但仍是系统设计不一致的表现。更为复杂的是地理唯一标识符DGUID存在大量无效或格式异常的情况。
Ripley通过构建正则表达式验证,检测出6037条疑似错误的DGUID记录,从而警示用户在使用地理空间数据时需谨慎处理标识符,避免地图可视化和地理分析中的错误匹配。例如,某些表格中缺少DGUID但包含地理字段GEO,显示出对跨国地理数据处理的挑战,同时也暴露了数据元信息管理的不足。 XML格式数据的下载同样存在问题。部分体积庞大的数据表,比如编号98100404,在XML格式下无法完整获取,仅获得结构文件(Structure.xml)而缺少实际数据文件,严重影响对XML格式数据的利用价值。由于XML格式本身冗长且解析复杂,建议用户优先采用优化后的Parquet格式进行分析,以提高性能和稳定性。 在硬件资源方面,面对超百GB级别的大数据表,单凭32GB内存的普通PC难以胜任数据完整加载和处理。
为此,Ripley通过设置高达400GB的交换分区(swapfile)以及调整Linux内核参数,增强系统对内存的管理和缓存处理能力,确保数据处理过程顺利进行。这一经验提醒广大处理大数据集的研究者和企业,硬件环境配置同样是数据分析成功的关键因素,需要合理评估和配置存储与内存资源。 未来,Ripley计划建立自动化的数据处理流水线,利用Dagster框架实现数据的定时更新和监控,保障数据的及时性和版本可追溯性。同时,计划将优化后的数据上传至Zenodo数据仓库,借助其版本控制和长久存储优势实现数据的可持续管理。针对用户需求,将开发基于DuckDB的Python和R API绑定,方便用户直接在编程环境中调用处理后的数据,并支持与地理边界文件的关联,提高数据分析的灵活性和可视化能力。 整个项目不仅对加拿大统计局的数据体系和API设计提出了建设性反馈,也为大规模官方数据集的处理与优化树立了范例。
通过技术创新和系统性的质量评估,统计数据的利用门槛被进一步降低,用户能够更高效地开展数据探索、统计分析和地理信息系统建设。未来随着自动化处理和开放API的完善,政府统计数据服务必将更加开放透明,推动相关领域的研究创新与数据驱动决策。 总的来说,加拿大统计局数据表的全量处理项目丰富了数据科学实践的案例库。它不仅关注了数据体积问题,更深入挖掘了数据质量、接口一致性、数据格式优化和应用场景。面对如此海量且多元的数据资源,科学的数据管理策略和先进的技术手段相辅相成,是发挥官方统计数据最大价值的保障。相关工作人员和研究者可借鉴这一实践经验,在自身工作中推进数据的标准化、结构化与高效化,助力大数据时代的智慧决策与社会进步。
。