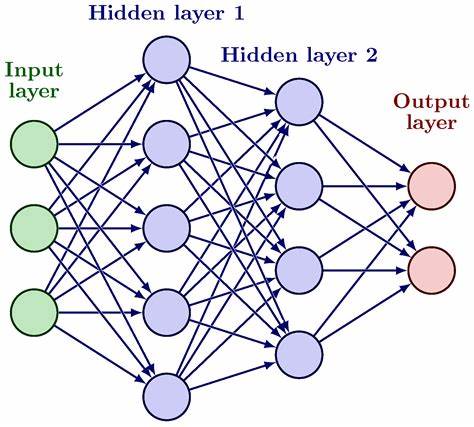
在远远看去,训练语言模型和数据加密似乎是截然不同的两个领域:前者通过学习样本中的模式以生成文本,后者则通过信息混淆来保护数据安全。但随着深入研究,人们发现神经网络和密码学密码的底层算法竟然存在着令人惊讶的相似性。本文将剖析这种相似的根源,解析它们在结构设计、功能需求和性能优化等方面的共通点。神经网络,尤其是序列处理模型,与密码学中的加密和验证算法,均以独特的方式处理输入数据,通过层层转换与混合,呈现复杂的输出。举例来说,传统的循环神经网络(RNN)对文本数据按顺序进行处理,将输入序列逐个token地融合进一个递归状态,再生成相应的输出文本。这种过程与密码学里的Sponge结构极为类似,后者在吸收(absorb)输入数据进入状态后,再通过挤压(squeeze)产生哈希值。
两者利用序列逐步累积并压缩信息,实质上是在处理可变长度的输入并凝练成固定尺寸的状态,这种设计本质上符合信息处理的自然规律。随着硬件性能的发展,序列的顺序处理模式由于无法充分利用并行计算能力而显得低效,因此两大领域一致采用了并行处理策略。将输入拆分为若干块,分别并行处理,再通过简单的加法将结果合并,上述方法虽然会导致数据的顺序信息在部分计算步骤中丢失,但通过位置编码技术,可以有效弥补这一缺陷。Transformer架构的出现正是基于这种并行思想,它革新了传统RNN的顺序处理模式,在自然语言处理领域引发了革命。而密码学中同样的设计理念被应用于高速消息认证码(MAC),确保既保证安全又能高效验证信息完整性。深入核心函数不难发现,神经网络与密码学算法都采用交替的线性变换与非线性变换构建层级结构。
线性变换负责状态中各元素间信息的混合,将数据从多个维度相互交织,而非线性变换则增加计算的复杂性,使得最终结果不会退化为简单的线性映射。通过多层的堆叠,比起精心设计的复杂结构,简单可复用的基本单元反而更适合深入研究和性能优化,甚至可以用简短的数十行代码实现核心算法。此外,这两个领域普遍采用将数据组织为矩阵或网格的结构,并交替对行和列进行混合处理。例如神经网络中的注意力机制就侧重跨越序列位置对行进行混合,而前馈神经网络则实现了列方向的处理;在密码学领域,AES密码算法通过ShiftRows和MixColumns操作实现了类似的行列交替处理。如此设计,不仅减少了算法复杂度,还提高了并行性,提升了硬件利用效率。背后的原因源自应用需求的共同点。
神经网络和对称密码学都对算法的正确性要求相对宽松。例如神经网络强调的是可微分性,这使得它们能通过梯度下降进行训练,而密码学更看重算法的可逆性以防止信息丢失,但并不要求输出和输入一一对应。宽松的正确性约束允许两者采纳极为简单但却重复迭代的原子操作,促进创新与快速试验。两者都重视输出的复杂性与信息混合质量。密码学需保持每个输出位复杂依赖于所有输入位,防止任何潜在信息泄露;神经网络则要求模型输出可以综合利用所有输入特征,实现准确预测与分类。为此,多轮多层次的信息交互和混合成为实现高质量结果的核心理念。
广泛的性能优化需求是另一个共性。由于加密技术的广泛应用以及神经网络规模与计算需求的激增,二者都对底层硬件的执行效率持极高关注。为了提升性能,简洁而可扩展的算法设计被优先考虑,易于在汇编级别优化或在专用硬件中实现,并利用并行计算最大化吞吐量。综上所述,神经网络与密码学算法的相似性并非偶然,而是两个领域在满足类似需求时,经过不同路径却趋同演化的结果。这种“算法的趋同进化”表明,当我们追求复杂多样的信息混合,允许算法设计保持高度自由,以及极力提升性能之时,结构上优秀而简单的方案自然会浮现。事实上,近年来两大领域的相互启发已开始显现,诸如可逆网络(RevNets)的发展直借鉴了密码学中的Feistel网络。
这或许预示着未来会有更多交易与融合诞生,带来更先进、更高效的算法架构。最后,随着人工智能与信息安全领域的不断壮大,深入理解并应用这些相似的算法设计理念不仅能促进技术创新,更能驱动两大产业的共同进步和提升。神经网络和密码学的惊人相似性,体现了技术发展的内在规律与人类智慧的巧妙体现,值得我们持续关注和探索。