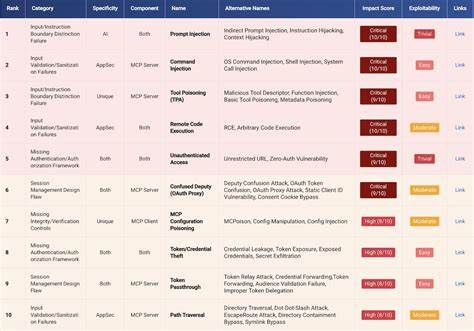
随着人工智能技术的飞速发展,保障AI系统的安全与稳定尤为重要。Model Context Protocol(MCP)作为Anthropic公司于2024年推出的开放标准,旨在协调数据源与人工智能工具之间的安全交互,成为连接AI代理、工具和数据的桥梁。然而,任何软件系统都无法避免安全漏洞的存在。近期,安全领域的专家团队Adversa发布了针对MCP的最全面漏洞分析报告,揭示了25项最为关键的安全隐患,这些漏洞可能威胁到整个AI生态的安全边界。MCP协议设计的核心目标是打造安全、可控且透明的AI工具交互环境,但随着使用范围的不断扩大,潜在风险也日益凸显。Adversa的研究通过系统化的方法对这些安全威胁进行了详细评估,采用综合评分机制将漏洞按影响力、利用难度、普遍性及修复成本进行排序。
在他们的评价标准中,漏洞的危害程度占比40%,漏洞的易利用性占30%,普遍度占20%,修复难度占10%。十大风险中,Prompt Injection(提示注入)荣登榜首。这种攻击方式允许攻击者通过构造恶意输入操纵AI模型行为,因其危害巨大且实施相对简单,成为当前AI安全领域的焦点问题。除了提示注入,还涵盖了身份验证缺失、数据泄露、权限提升及恶意代码执行等众多严重威胁。尽管目前业界尚无权威组织针对MCP发布统一的十大安全问题,OWASP正在积极制定相关标准,Adversa团队的这份25项漏洞清单已然成为行业参考的先行者。该报告不仅列举了每个漏洞的正式名称及其常见别名,还提供了详细的安全影响分析与利用条件说明。
通过这些数据,开发者能够评估自身系统的风险暴露情况及优先修复级别。安全专家强调,防止这些漏洞被恶意利用的第一步是严格验证所有输入。数据显示,有43%的MCP服务器容易受到命令注入攻击,因此,输入校验与清理机制不可或缺。Adversa建议采用多层次防护战略,将防护措施分布在协议层、应用层、专门针对AI的安全措施以及基础设施层。协议层方面,强制支持TLS加密确保所有通信通道的机密性及完整性。应用层则需使用参数化数据库查询以防止SQL注入及其他命令注入风险。
在AI特定安全措施中,建议建立模型行为监测体系,实时捕获异常请求和结果,防止模型被恶意诱导。基础设施层则强调部署多重身份认证与访问控制,限制未经授权的访问尝试。在漏洞修复进程中,Adversa提出了一个循序渐进的三个月缓解时间表,初期重点在于立即加强身份验证,同时逐步推动架构转型,逐步推行Zero-Trust模型,强化整体防御能力。值得注意的是,除了技术手段外,安全防护也需要企业组织的协同配合。开发人员、运维工程师与安全团队需携手制定完善的安全政策和流程,及时更新和应对新威胁。MCP漏洞的复杂性和多样性也要求持续关注既有安全文档和CVEs,快速响应最新攻击事件,确保安全态势的动态防护。
整体来看,MCP作为AI生态的重要组成部分,其安全问题不容小觑。随着AI应用场景日益多元复杂,面临的攻击面和攻击手法也将不断演化。借助Adversa发布的漏洞榜单和防护策略,相关企业和研发团队可以更加清晰地定位安全盲点,采取科学有效的措施降低风险。未来,随着OWASP等权威机构正式发布MCP安全标准,这些工作将进一步规范行业行为,提升整个AI领域的安全基础。总而言之,保障MCP协议的安全是保障人工智能系统健康发展的基石。认真对待每一项漏洞,合理部署分级防护,积极实施Zero-Trust架构,都是提升系统稳健性的关键路径。
面对当下日益复杂的安全挑战,唯有将技术与管理相结合,打造全方位多层次的防御体系,才能真正守护AI的未来,让人工智能安全、可信地服务于社会、经济各领域的发展需求。 。