引言 在大规模语言模型成为主流的今天,预训练模型参数量常以数十亿到数万亿计,而后续的微调任务通常只涉及相对小得多的数据量。直接对全模型参数进行微调(FullFT)在精度上有其优势,但在算力、内存和部署复杂性方面代价不菲。低秩适配(LoRA, Low-Rank Adaptation)作为参数高效微调(PEFT)的代表,通过把每个权重矩阵替换为原权重加上低秩修正项 W′ = W + γBA,以极小的额外参数实现显著的定制化能力,因而在工程实践中获得广泛关注。本文系统梳理 LoRA 在不同场景下的行为特征、主要优势与局限,并给出可直接落地的超参数与工程建议,以便在成本与效能之间取得无悔的平衡。 LoRA 的核心价值与工程动机 LoRA 的思路很直接:把更新限制在低维子空间,使得微调只需存储和传输 A、B 两个矩阵而非整个模型权重。这样带来几项现实好处。
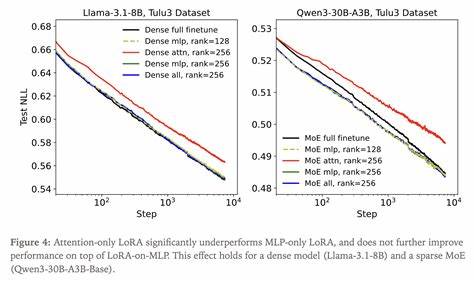
首先,在多租户推理场景下,原始模型保持不变,服务器可以同时加载多个 LoRA adapter,按需组合输出,极大简化版本管理与快速切换。其次,训练时所需的优化器状态与梯度内存大幅下降,许多情况下 LoRA 可以在与推理接近的布局上完成训练,降低对大型集群的依赖。最后,adapter 文件小、加载快,便于分发与协同开发。 LoRA 在监督学习中的表现与容量边界 大量实验表明,在典型的后训练(post-training)数据规模下,LoRA 可以在样本效率和最终精度上与 FullFT 相当,前提是两点得到满足:LoRA 被应用于模型中的大部分参数矩阵,尤其是 MLP 与 MoE 层;以及 LoRA 的参数总量不会低于训练所需的信息量。实证上,当将 LoRA 限制在注意力层时(attention-only LoRA),模型学得较慢且最终效果通常逊色于把 LoRA 应用在 MLP 层或全层的配置。该现象并非仅由参数数量差异解释,而更可能与不同层对学习信号的贡献(例如经验神经切核 eNTK)有关,参数占比大的层对损失梯度内积的影响更显著,因此把 LoRA 放在这些层上能更好地重现 FullFT 的微调动力学。
关于 rank(秩)与容量:当 rank 较大时,LoRA 的学习曲线与 FullFT 在对数步数尺度上几乎重合;当 rank 缺乏时,训练曲线会逐渐偏离最优轨迹,表现为学习效率下降而非立刻陷入固定下限。因此,从工程角度看,应根据数据规模估算所需信息量,再选择使参数容量超过预估信息量的 rank。对于监督任务,训练集样本数与损失值可用来上界所需位元,结合 LoRA 参数数量(约为每层 rank*(din+dout) 的和)做决策。 LoRA 在强化学习中的强势表现 强化学习(尤其基于策略梯度的设置)对单次样本传递的信息量远小于监督学习。策略梯度的核心更新由优势值(advantage)传递信息,最多为常数阶比特量,这意味每个训练 episode 为模型带来的可学信息相对有限。实验表明,在数学推理等 RL 任务中,LoRA 即便使用极低的 rank(如 1)也能在最终性能上匹配 FullFT。
直观上,LoRA 参数即便很少,仍比每次训练回合提供的信息量多很多,因此容量不成瓶颈。对需要用 RL 微调大模型以改进行为或偏好设置的场景,LoRA 因其计算与内存优势成为天然的首选。 学习率、初始化与参数不变性 LoRA 的参数化形式带来若干有助于超参数迁移的特殊性质。常见的实现将修正项写做 α/r · B A,其中 α 为缩放因子,r 为 rank。引入 1/r 因子后,训练初期的预期更新几乎与 rank 无关:把 BA 看成 r 个秩一矩阵之和时,平均后的更新在期望上独立于 r,这解释了为何不同 rank 在训练早期呈现相似曲线。实践中发现,LoRA 的最优学习率普遍高于 FullFT,大致有一个稳定的经验比例:LoRA 的最优学习率约为 FullFT 的 10 倍,短跑式训练(短步数)中这一比例可能更高,长训练时会趋近于 10x。
对工程师而言,一个有效的经验法则是从 FullFT 的学习率乘以 10 作为 LoRA 的起点,再进行细化。 进一步地,LoRA 有几对可变超参数存在规模不变性。若对 α、A 的初始化尺度、以及 A、B 的学习率做联合缩放(可用两个正数 p、q 实现),在 Adam 优化器下训练轨迹保持不变(或仅受 ε 修正)。因此实际调参时可把注意力集中在两个自由度上:决定初期更新幅度的组合量(α·initA·LRB)与 A 本身变化的时间尺度(initA / LRA)。将这些解释融入调参流程能减少盲目网格搜索的范围。 批量大小敏感性与优化动力学差异 实验还表明 LoRA 在某些数据集上对大批量训练的容忍度低于 FullFT。
随着 batch size 增大,LoRA 相比 FullFT 的性能劣化更明显,且这种差异并不随 rank 改善。造成这一现象的候选解释是 BA 的乘积结构改变了局部优化景观和随机梯度噪声的影响方式,使得在同等大 batch 下收敛效果变差。工程上建议:当选择 LoRA 时优先尝试中小批量(例如 32 或 128),若确需大批量以提高吞吐率,则需额外验证性能损失,并考虑通过更保守的学习率或更长的训练步数来补偿。 如何把 LoRA 应用于 MoE 与长上下文场景 把 LoRA 用在专家模型(Mixture-of-Experts,MoE)上时,一个务实策略是对每个专家分别训练 adapter,并把总 rank 按激活专家数做缩放,使得 LoRA 相对于 FullFT 的参数比例在 MoE 层与常规层保持一致。这样既能保留 LoRA 的参数优势,也避免某些专家因参数过少而学不到特定能力。在长上下文设置中,注意力计算本身可能成为 FLOPs 与显存的主导项;LoRA 在权重更新 FLOPs 上节省的比率仍然明显,但总体训练瓶颈需要结合具体模型架构与序列长度综合评估。
计算效率与成本对比 从浮点运算视角分析,单个权重矩阵的前向和反向传播中 FullFT 大约需要 3N^2 的乘加操作;而 LoRA 在替换为 W+BA 后,针对 A、B 的前后传递与更新成本约为 6NR,再加上对原始 Wx 的计算,整体 FLOPs 约为 2N^2 + 6NR。对于 R≪N 的情况,这意味着 LoRA 每步 FLOPs 大约为 FullFT 的 2/3 左右,从而在相同步数下通常更节省计算资源。如果按 FLOPs 或实际训练时间评估训练效率,LoRA 的优势会更明显,这也是它在工程上备受青睐的一个重要原因。 可操作的工程建议与调参流程 针对工程团队与研究者的实际需求,给出若干可直接落地的建议。把 LoRA 应用于模型的 MLP 与 MoE 层至少应作为默认选项;只对注意力层做 LoRA 可能导致性能下降。初始化方面,采用 A 随机初始化(标准差 ~1/din)且 B 初始化为零的组合是一种稳健选项;常用缩放 α=32 能在多数场景下发挥良好效果。
学习率起始点可前置:以 FullFT 的最佳 LR 为基准,尝试 LoRA LR = 10× FullFT LR,并在该范围内做局部搜索以找到最优值。对短时训练任务(步数非常少),考虑增大 LR 的倍数以加快初期学习,但需警惕不稳定。batch size 建议以中等为优,若必须大 batch,应通过更细粒度的 LR 与步数调整来补偿性能损失。rank 的选择应由数据规模与任务复杂度驱动:监督场景下把 LoRA 参数总量尽量覆盖估算的信息上界;强化学习场景可从极低 rank 开始,通常表现足够。 未解的理论问题与未来方向 尽管实证证据逐渐完善,LoRA 的若干理论问题仍待解答。为什么 LoRA 的最优 LR 与 FullFT 存在稳定的 10x 比例?这个比值对网络规模与体系结构的普适性如何?LoRA 在极大数据量与"预训练级别"规模的数据上会如何退化?不同 LoRA 变体(例如以奇异方向为适配子空间的 PiSSA)在相同评价协议下的表现如何?这些问题对于把 LoRA 的实用边界精确化非常重要。
此外,MoE 场景、专家间并行与 tensor-parallel 的兼容性研究也将决定 LoRA 在超大模型上的可扩展性。 结语 LoRA 在多数后训练场景中提供了一个低风险、高回报的替代方案:它能显著降低训练和部署成本,同时在样本效率与最终性能上接近甚至匹配全量微调。关键在于把 LoRA 放在模型的重要参数区域(如 MLP/MoE 层)、合理选择 rank 以确保不受容量约束,并沿用合适的超参数策略(如学习率约为 FullFT 的 10× 起点、α=32、A 随机初始化、B 置零)。面对未来更复杂的任务与更大的数据集,LoRA 仍有许多值得探索的空间。对于希望以更低成本把大模型快速应用到具体任务的团队而言,LoRA 是一个值得优先试验的工具,其"无悔"的特性在大多数常见后训练情形下都能得到体现。 。