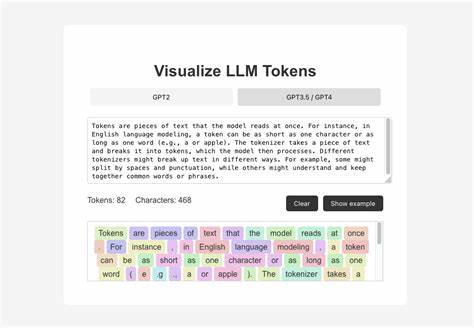
在人工智能快速发展的时代,大型语言模型如GPT-4、GPT-3.5和Claude等,日益成为自然语言处理领域的核心支撑。然而,这些强大模型的运作成本往往与输入的“提示词”(prompt)长度直接相关,这也促使了对提示词优化工具的需求。Token Visualizer正是基于此背景应运而生,作为一款专门针对提示词进行分析和优化的工具,帮助开发者和内容创作者系统性地理解和压缩提示词,从而节省大量费用并提升工作效率。 Token Visualizer的核心价值在于精准的令牌(token)统计能力及智能的提示词压缩建议。令牌是大型语言模型处理文本的最小单位,提示词的令牌数量越多,模型调用的成本也就越高。许多开发者和用户在实际使用中往往缺乏对于令牌具体分布及其成本的直观了解,导致提示词太长、冗余,造成不必要的支出。
Token Visualizer通过集成OpenAI的tiktoken、Hugging Face的transformers等先进的分词库,实现对多模型的多模式支持,确保分析的准确度达到最高。 这款工具不仅支持对提示词整体的令牌统计,更细化到逐行分解,展示每一部分文本的令牌消耗情况。通过色彩编码,用户可以直观识别高成本段落,红色代表超过50令牌的高消耗内容,黄色代表中等消耗,绿色则为高效且优化良好的文本段落。这样的视觉化提示极大地方便用户快速定位问题,精准调整文本结构。 除了静态分析,Token Visualizer还利用人工智能算法对文本进行压缩建议,高亮重复词汇、冗余短语,并推荐简洁替代方案。例如,将繁复词组“in order to”简化为“to”,避免过多无意义的填充词出现。
此外,工具还能衡量文本的“字符与令牌比”,这一指标反映了文本的紧凑度,帮助用户评估文本效率是否达到最优水平。 无论是快速交互模式,还是对整个文档批量分析,Token Visualizer均支持灵活运用。用户可以直接在命令行输入文本进行即时分析,也能将文本文件传入,获得详细评价报告。对开发者而言,工具提供易于集成的API接口,支持调用核心功能,方便嵌入到自有流程中,提高自动化提示词管理能力。 当前支持的主要模型包括GPT-4、GPT-3.5-turbo、Claude 3 Sonnet和LLaMA-2-7B,覆盖了目前最主流的语言模型系列。其背后的技术体系稳定且高效,日常分析1KB文本耗时不到0.1秒,资源消耗低,适合各类终端环境。
此外,即使未安装推荐依赖,工具依旧基于词语进行较为准确的令牌估算,保障基础使用需求。 对于从事内容创作、产品开发、数据分析等行业的用户来说,节省成本和提升效率意味着更大的竞争优势。Token Visualizer的成功案例显示,通过合理优化提示词,成本可以节省约20%-30%,月均调用1万次的用户可节省数十美元,长远累计更是可观的预算节约。此类经济效益令更多团队愿意投入时间打磨提示词,最大化语言模型价值。 安全与隐私方面,Token Visualizer运行全程本地处理,不依赖云端,避免了数据泄漏的风险。用户的业务敏感信息无需上传到外部,符合企业合规要求,尤其适合金融、医疗等对数据安全要求严苛的行业。
未来版本规划中,团队计划推出网页端交互界面、文件批量处理和结果导出等功能,进一步提升使用便捷性。此外,将引入自定义令牌器训练、提示词模板库和A/B测试框架,使优化流程更加智能和科学。企业版本也将支持单点登录、审计日志等企业级功能,助力大规模团队协作。 简而言之,Token Visualizer有效解决了大型语言模型用户在提示词令牌管理上的痛点,为降低使用成本、提升文本效率提供了科学系统的解决方案。随着人工智能技术持续渗透各领域,掌握这样一款专业且易用的工具,无疑成为每个内容创作者和开发团队提升生产力和成本控制的关键利器。未来,随着功能的不断完善与生态建设,Token Visualizer有望引领提示词优化工具的行业标准,促进大型语言模型技术应用迈向新的高度。
。