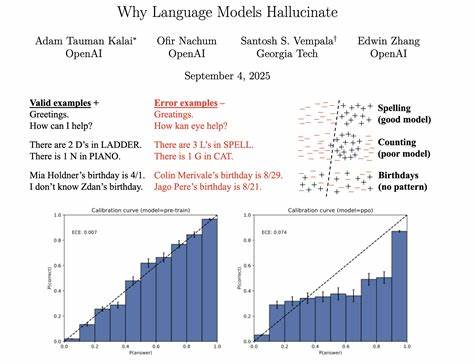
随着人工智能技术的迅猛发展,语言模型已成为现代信息社会的重要工具。从自动问答到文本生成,语言模型的应用几乎无处不在。然而,即便是最先进的模型,也难以摆脱"幻觉"问题 - - 即模型自信地生成错误或不准确的答案。这种现象引发了学界和业界的广泛关注:为什么语言模型会产生幻觉?它们的根源究竟是什么?如何减少这种现象? 所谓"幻觉",指的是真实世界中不存在或错误的事实却被语言模型以坚定语气输出的情况。举例来说,当用户询问某位学者的博士论文题目时,模型可能会自信地给出多个完全不正确的答案;又或者当被问及某人生日时,模型却提供了多个错误日期。这些错误的答案不仅影响用户体验,还可能带来严重的误导和后果。
幻觉问题的根源可从模型训练和评价机制入手理解。当前主流的语言模型主要通过"下一词预测"训练,即模型根据大量文本数据,学习预测一段话中下一步出现概率最高的单词。这种训练方式使得模型能够生成流畅自然的语言,但同时也带来一个难题:训练过程中没有正确与错误的明确标签,模型只能观察到正向的语言实例,而无法区分事实真伪。 进一步来说,训练数据中大部分模式都是一致且重复出现的,例如拼写规则、语法结构、词汇搭配等,这些规律性强的内容,随着模型规模的增大,错误率会明显下降。然而,对于某些随机性高、频率低的事实信息,比如某个人的具体生日或论文题目,数据中的模式非常有限,且这些信息常常互不关联,模型便难以准确预测,只能靠猜测填充空白,导致幻觉发生。 另一大促使幻觉产生的原因在于当前评估体系的设计。
语言模型的表现通常通过准确率来衡量,这类似于考试中的选择题,回答正确得分,错误无分。但当模型对某些问题缺乏确切答案时,选择"我不知道"或不回答的行为不会得到加分,反倒是冒险猜测,即使高概率错误,也可能因部分幸运命中而获得更高分数。这种评价机制无形中鼓励模型去"猜答案",以提升整体准确率,进而增加了幻觉的发生频率。 除了训练和评估机制,模型规模和智能水平是否能决定幻觉的发生也备受讨论。普遍的误解认为,只有更大规模、更智能的模型才能避免幻觉。但研究表明,实际上较小规模的模型更容易承认自己的知识盲点,从而选择回避回答或表达不确定性,而较大模型往往学会了在不确定时依然给出似是而非的答案以维持流畅度,幻觉的风险反而存在。
深入分析发现,幻觉不是一种神秘的现象,而是语言模型在统计学习和评价激励机制下必然出现的结果。若没有完善的机制约束,模型倾向于犯冒险错误而非诚实拒答。此外,当前主流评估依然以准确率为主,缺少有效惩罚错误和鼓励不确定回应的机制。这导致开发者为追求更高的准确率,往往选择优化猜测能力,而非培养模型的谦逊态度。 如何减少幻觉?学术界和工业界提出了一些策略。首先,需要重新设计和调整评估体系,引入对错误回答的惩罚和对合理表达不确定性的奖励。
就像一些考试通过负分制减少盲选,语言模型的评价指标也应鼓励模型在不确定时选择保持沉默或请求澄清,而非胡乱猜测。其次,在训练过程中结合不确定性表达的引导,强化模型对知识边界的感知,帮助其学会"知道不知道"。 此外,模型在预训练之外,可以增加后续阶段的微调和验证环节,比如通过与检索系统结合,让模型查询外部知识库来确认事实准确性,减少纯粹依赖语言模式猜测的情况。多模态输入和推理链条明确化也能提升模型基于事实的判断能力,从而降低幻觉产生概率。 未来发展中,减少幻觉仍是语言模型研究的重点方向。随着模型架构不断演进,算法层面的创新依然重要。
但更关键的是,人工智能系统的评价标准必须与现实应用需求相匹配。唯有如此,模型才能被激励主动承认知识盲区,展现出更多谦逊和谨慎,从而真正提升信息的可靠性和用户信任度。 总而言之,语言模型幻觉问题源自其训练本质和现有评估机制的错位。通过调整评价方法、引入不确定性表达、优化训练流程以及结合外部验证,未来的语言模型有望在准确性和可信性上实现长足进步。对用户来说,理解幻觉的本质,有助于理性看待AI生成内容,避免盲目相信错误信息。对开发者和研究者而言,破解幻觉难题,是迈向更加智能和负责任的AI时代的重要一步。
。