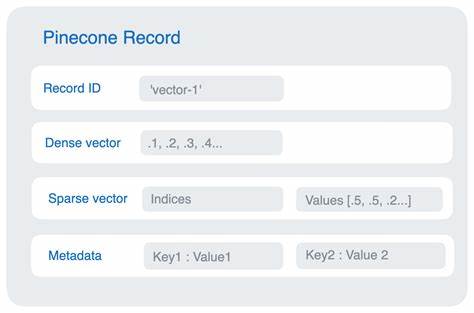
随着人工智能应用的不断发展,向量数据库在大规模语义搜索和信息检索中的重要性日益凸显。Pinecone作为一款领先的无服务器向量数据库平台,专注于为动态且庞大的数据集提供高效的语义检索能力。在众多技术挑战中,如何在保证准确性的基础上,实现对元数据的高效过滤,成为Pinecone致力攻克的关键难题。本文将深入解析Pinecone的元数据过滤机制,剖析其架构设计及实际性能表现,帮助读者全面了解Pinecone如何通过创新技术实现精准而高效的元数据过滤。向量数据库的独特优势在于其能够结合向量相似度与传统数值及类别型元数据共同构建复杂查询,从而提升检索结果的相关性和业务价值。例如,在检索增强生成(RAG)系统中,不仅要找到语义上相似的文档,还要结合文档类型、时间戳、用户上下文等元数据进行过滤,以保证生成内容的准确度和时效性。
然而,元数据过滤的实现并非易事,尤其是在无服务器环境下,计算资源与存储资源分离,数据频繁插入、删除及更新,元数据与向量索引却又需保持高度一致,过滤的正确性和效率面临严峻挑战。Pinecone在其最新发布的研究论文中介绍了其元数据过滤的创新设计思路。核心做法是将过滤操作深度整合到向量检索路径中,而非作为后期单独处理,这样能有效确保过滤的准确性和计算效率。Pinecone采用基于不可变向量区块的结构,这些区块按照日志结构合并树(LSM-tree)组织,存储于对象存储系统,保证了数据的稳定性和高效访问。基于此架构,查询时的执行器保持无状态,按需触发,降低了资源消耗和系统耦合度,同时引入新颖的协调机制以确保检索时的过滤条件与索引状态保持一致。这一设计不仅提升了检索过程的响应速度,更确保了元数据过滤的准确回召。
Pinecone还针对过滤操作的不同应用场景,定义了两种基本交互模式:一种是动态即时过滤,针对临时生成的过滤条件进行查询;另一种是预计算过滤表示,对常用过滤条件提前生成对应索引,优化查询性能。通过对比两种方式,Pinecone分析其在性能和准确性上的权衡,为用户提供灵活且高效的选项。为了验证方案的实用性和稳定性,Pinecone在公开的过滤搜索数据集(如YFCC)上进行了性能测试,并结合真实生产环境中的客户数据展开实测。这些数据包含丰富的类别与数值型字段,测试结果显示Pinecone能在保持过滤准确无误的前提下,支持大规模数据的快速检索,响应时间和吞吐量均达到了业界领先水平。Pinecone的元数据过滤技术不仅在学术研究中具备显著贡献,更在行业应用中展现出强大竞争力。许多企业在构建知识图谱、对话系统和推荐引擎时,依赖Pinecone实现复杂多维度的查询需求,有效提升了系统智能化水平和用户体验。
展望未来,随着向量数据库技术与人工智能深度融合,元数据过滤的重要性将愈加突出。Pinecone在架构设计上的创新为行业树立了标杆,也为开发者和企业提供了具有广泛适用性的解决方案。同时,Pinecone持续优化性能,探索多模态元数据和上下文感知过滤等前沿方向,助力AI应用实现更精准的知识获取与信息检索。在当今数据爆炸的时代,向量数据库的性能瓶颈和准确性问题亟需突破。Pinecone通过其精准高效的元数据过滤技术,不仅保障了检索结果的质量,还大幅降低了系统资源消耗和运维复杂度。对于研发者而言,理解Pinecone的设计理念和技术实现,有助于更好地利用其平台优势,构建面向未来的智能应用生态。
归根结底,元数据过滤作为连接向量搜索与实际应用需求的桥梁,是提升AI服务响应能力和内容相关性的关键。Pinecone的解决方案展示了如何在无服务器架构下,通过巧妙的数据结构设计和协调机制,实现高准确率与高效率的完美平衡。无论是面向文本检索、图像搜索,还是多模态融合,这套方案都具备广泛适用性,为行业发展注入新活力。总而言之,精准且高效的元数据过滤是推动向量数据库迈向实用化和商业化的核心技术之一。Pinecone凭借领先的研究和实际产品,已经构建出一条可持续发展的技术路径,为人工智能赋能的数据检索革命贡献了宝贵力量。未来,随着技术持续迭代与应用场景的不断扩展,Pinecone有望继续引领向量数据库领域的创新浪潮,推动AI智能检索技术迈上新的台阶。
。