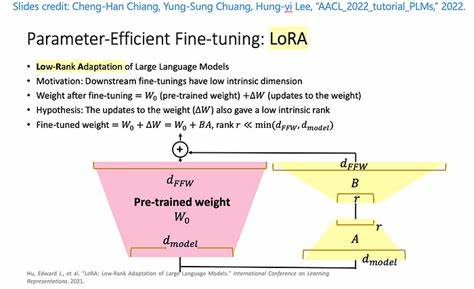
随着人工智能的迅速发展,大型语言模型(Large Language Models,简称LLMs)已经成为自然语言处理领域的核心工具。它们凭借海量参数和强大表现力,推动了从文本生成到对话系统的多种应用创新。然而,庞大的模型规模带来了极高的训练和微调成本,特别是对于资源有限的用户来说,依赖昂贵的GPU进行微调几乎无法实现。传统方式中,利用GPU进行模型微调成为常态,这不仅导致高昂的硬件投入,还限制了模型在更广泛环境中的普及和应用。针对这一问题,低秩适配器(Low-Rank Adapters,LoRA)技术应运而生,成为参数高效更新的利器。它通过调整模型中部分权重的低秩表示,实现对大型语言模型的轻量级微调,大幅降低了计算资源的消耗。
然目前该技术仍严重依赖GPU计算,极大限制了普通用户和开发者的使用场景。近期,一份由Reza Arabpour等研究者发布的顶尖学术论文提出了一种创新的CPU高效LoRA微调框架,为解决这一瓶颈提供了全新思路。该方法跳脱传统梯度计算,采用元生成技术,通过预训练的LoRA权重库构建适配器,使模型微调过程无需进行繁重的GPU训练,能够直接在笔记本电脑等普通CPU设备上完成微调任务。这一理论上的突破与工程实现不仅拓展了LoRA技术的应用边界,也为普及大型语言模型提供了实用而经济的路径。本文将从技术原理、实现方式、性能表现及未来发展等方面,详细揭示CPU环境下LoRA微调技术的核心价值。首先,从技术机制上看,该CPU微调框架基于一个庞大的预训练低秩权重库,针对Mistral-7B-Instruct-v0.2模型构建。
核心思想是通过学习一个映射操作符,这个元操作符能够将任意输入数据集的概率分布转换为一组优化的LoRA权重。换言之,无需重新进行梯度下降等耗时训练步骤,系统直接组合已有的适配器权重,通过线性加权方式快速生成新适配器。该方法极大地降低了计算负担,尤其摆脱了GPU算力瓶颈,实现真正意义上的CPU端微调。其次,性能验证表明,尽管这种生成式适配器权重不能完全媲美传统GPU微调的准确度,但明显优于未调优的基础模型,且在多种下游任务中展现出稳定可靠的能力。对于有限计算资源者而言,这种稍有折损但依然显著提升的方案,是加速模型部署的福音。值得关注的是,该技术还保持了高度的灵活性,用户只需提供数据分布特征,系统即能快速迭代合成合适的LoRA参数,无需深入理解梯度优化细节,显著降低使用门槛。
随着大型模型向低成本、高效率方向发展,这一技术路线契合实际需求的转变趋势。再者,从应用层面看,CPU环境下的LoRA微调框架极大促进了模型的民主化。过去,因高昂的GPU成本,许多中小企业、科研机构和个人开发者被阻挡在最新模型技术之外。如今,他们能够使用常规笔记本或办公电脑进行定制化模型调优,应用范围涵盖智能客服、内容生成、教育辅助等多个领域。此外,结合云端计算与边缘推理,CPU微调技术为分布式AI服务提供了灵活方案,推动模型在嵌入式设备和低功耗场景的落地。未来展望方面,该技术还具备多方向提升空间。
其一,可以通过扩充和细化预训练LoRA库,提高生成适配器的多样性与性能;其二,有望融合自适应元学习算法,实现更快、更精准的权重映射;其三,进一步优化计算效率和内存使用,使之支持更大规模模型及复杂任务。与此同时,随着人工智能生态的不断成熟,跨平台、跨设备的统一调优方案将成为趋势,CPU适配方法必将成为关键环节之一。总结而言,无需GPU的LoRA微调技术开辟了大型语言模型个性化定制的新道路,以其低成本、易操作的特点,有望广泛激活AI应用的创新潜能。它不仅缓解了资源瓶颈,也促进了人工智能研究与应用的公平性与多样性。未来,随着方法的不断完善与生态建设,基于CPU的轻量级微调或将成为行业标配,推动AI向更普惠、高效的方向演进。对所有关注人工智能落地、技术普适化的开发者与从业者而言,紧跟并掌握这一趋势,绝对不容错过。
。