近年来,随着生成式人工智能技术的迅猛发展,大型语言模型在自然语言处理、文本生成、代码编写等领域展现出巨大的潜力。然而,在这一波热潮背后,如何有效地与这些模型协同工作,打造稳定、精确且可扩展的应用,已成为技术团队面临的重要挑战。上下文工程作为一门新兴的复合学科,正迅速成为连接人工智能能力与实际产品的桥梁,重塑着构建AI产品的思维方式。 在早期,开发者们往往将关注点放在"提示工程"(Prompt Engineering)上,尝试通过巧妙地撰写提示文本来引导模型产生理想的结果。然而,随着业务场景复杂度的提高和模型规模的扩展,单一的提示文本往往难以满足需求。此时,必须跳出对单一"提示词"有效性的追逐,转向对整个上下文信息环境的系统设计与优化,这正是上下文工程的核心意义所在。
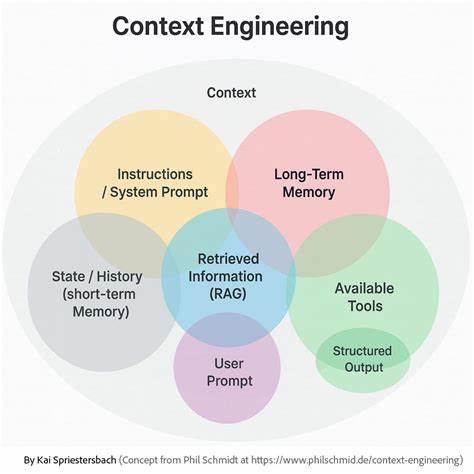
所谓上下文工程,是指设计、构建和持续优化输入给大型语言模型的整个信息环境,包括指令、状态管理、动态检索到的数据以及格式化方式等多方面内容。简而言之,它将LLM的调用视为一个非确定性的函数,输入是由上下文组成的字符串,输出是相应生成的文本。工程师的目标就是构造最优的上下文,使得模型在这"一根线"的输入下,能够完成多样且复杂的任务。 采取这种视角,开发者不再把LLM当作"懂人类语言的助手"或"拥有理解能力的实体",而是把它抽象为一个黑箱函数。理解模型无记忆、无意图、输出带有概率性的特点,能帮助我们设计更健壮的系统,避免因错误假设产生的系统失效。这种"通用函数"的心智模型明确了责任边界:模型自身的能力是固定的,所有的控制权均来自对上下文的精准管理。
上下文工程的实践包含多方面内容。首先是指令部分,传统提示工程依然发挥重要作用,通过设定角色身份、提供明确的操作步骤以及示范期望输出格式,提高生成内容的引导性和稳定性。其次,状态管理在交互式应用中尤为关键。由于LLM本身无状态,维持对话或多步流程的状态信息必须显式封装进上下文。例如聊天机器人会积累上下文消息,应用则可能需包含用户偏好、历史操作等信息。考虑到上下文窗口的容量限制,还要采用摘要或滑动窗口等技术确保最新且关键内容得以保留。
当前一个重要的架构趋势是检索增强生成(RAG)系统。通过动态检索外部知识库或实时数据,RAG有效降低了模型的"幻觉"风险,使生成结果更为准确且具时效性。RAG不仅丰富了上下文的信息来源,也成为许多知识密集型应用的基石。高级的RAG系统甚至结合智能代理,利用多轮检索、多模态工具调用和推理过程,动态构建更完备、更契合任务需求的上下文。 上下文工程的成功,离不开严谨而系统的方法论指导。鉴于LLM输出的非确定性,每一次上下文修改后的结果都需经过科学的实验验证。
工程团队应从明确期望输出着手,定义理想答案的内容、格式和语气,进而倒推设计上下文组成和信息管道。接着分阶段实施:从数据采集、检索优化、上下文合成,到最终的端到端测试。每个环节均应独立验证,确保功能正确后再进行整体整合,减少问题定位难度。 此外,持续的实验与迭代是提升系统表现的关键。借助精准的性能指标和自动化测试,团队能够量化改动效果,有针对性地进行调整。该方法将构建生成式AI系统从艺术化的提示创作转变为工程化的系统设计,显著提升了可维护性和可扩展性。
随着上下文工程逐渐成为生成式AI开发的标准实践,理解其核心理念尤为重要。首先,开发者应摒弃关于模型"理解"或"记忆"的误解,牢牢树立"模型为非确定函数"的思维模式。其次,构建复杂应用的重点不再是单条提示,而是设计一个涵盖指令、状态、检索和格式化等多元数据源的流水线式上下文生成系统。最后,这一过程必须依托严密的实验与度量支持,保证产品质量和用户体验持续优化。 未来,伴随模型能力的进一步提升和上下文工程方法的成熟,生成式AI产品将变得更加智能、灵活和可靠。对于技术团队而言,把握上下文工程的核心方法,不仅意味着掌握先进的AI构建技能,更是一项在快速演进的行业中保持领先的必备能力。
总之,上下文工程重塑了传统的AI开发思维,推动从"凭感觉的提示创作"迈向"科学化的系统设计"。它帮助我们更深刻理解大型语言模型的工作机制,搭建可信赖的生成流程,并最终实现人工智能技术的商业化落地。作为生成式人工智能时代的关键技能,掌握上下文工程,无疑将为开发者打开通向高效、安全且可扩展AI应用的大门。 。