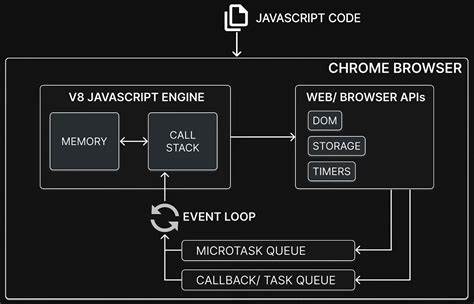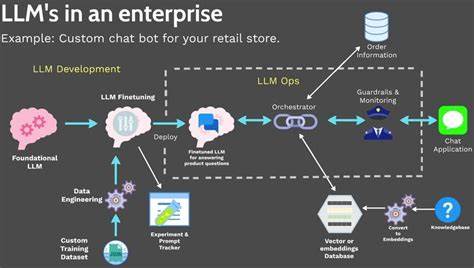
随着人工智能技术的飞速发展,大型语言模型(LLM)因其强大的自然语言处理能力而备受关注。然而,越来越多的个人开发者和中小企业开始考虑是否应当自行搭建并托管自己的大型语言模型。虽然这种想法听起来极具吸引力,能够实现绝对的数据掌控和定制化需求,但背后隐藏的技术复杂性、巨额成本和潜在风险可能远超想象。本文将深入剖析自行托管大型语言模型的关键陷阱,帮助您全面了解其背后的挑战及更合理的选择策略。 首先,搭建大型语言模型对硬件设施的需求极为苛刻。主流的先进模型往往拥有数百亿乃至数万亿参数,单是训练环节就需要成百上千甚至更多高性能GPU的支持。
这不仅意味着需要具备庞大的资金投入,还需解决复杂的硬件布局、冷却系统、电力保障等一系列基础设施难题。对于绝大多数个人或中小企业来说,购买、安装和维护这些专业硬件设备的成本显得遥不可及,甚至超过了整个人工智能项目其他部分的预算总和。此外,硬件的快速迭代带来升级压力,长期运营成本维持高昂。 其次,自行训练或微调大型语言模型对专业人才的依赖极高。AI模型构建不仅需要了解深度学习理论和程序开发,更需掌握分布式计算、大规模数据处理以及算法优化等交叉技能。聘请一支经验丰富的专业团队意味着高昂的人力成本,同时人才市场竞争激烈,招募和留任成挑战。
没有专业团队支撑,项目很难保障训练效率和模型质量,训练错误带来的返工风险极大。即使采用预训练模型进行微调,也需精细设计算法及参数,稍有不慎便可能导致模型表现不佳甚至出现偏见和漏洞。 数据问题同样不可忽视。大型语言模型需要海量、优质且多样化的训练数据。如何合法获取、清洗并构建有效的数据集,是一项庞大且复杂的工作。数据隐私与合规风险尤为重要,未经授权或包含敏感信息的数据可能招致法律纠纷。
此外,数据的持续更新和维护是保证模型时效性和准确性的关键。然而数据标注和管理又需要耗费大量的人力资源,且存在潜在偏见风险,直接影响模型的实际表现。 安全性方面,自行托管大型语言模型面临显著挑战。模型的开放接口可能被黑客利用,进行数据窃取、模型窃密或注入恶意代码。此外,模型本身存在生成有害内容的风险,如何设置合理的限制和监控机制尤为重要。对于非专业团队,构建全面的安全防护体系极具难度,这直接关系到用户数据安全和企业声誉。
相较于成熟的云端AI服务提供商,其安全防护和监控机制更加专业和完善。 在性能优化方面,模型推理和响应速度要求极高。要保证用户交互的实时性,需要设计高效的计算架构和调度机制。不合理的部署可能导致延迟严重、资源浪费甚至系统崩溃。自行托管过程中,缺乏实时监控和自动扩缩容能力,极易导致服务不稳定,影响用户体验。与之相比,云端平台提供高度弹性和稳定的运算资源支持,更加适合需求波动较大的应用场景。
成本方面,自行托管初期投入庞大且周期长,后续运维成本同样不可忽视。硬件折旧、人力薪资、电力消耗和网络费用均构成持续的经济压力。同时,技术升级和模型迭代需要不断追加投入,投入产出比往往不及云端订阅模式灵活合理。很多初创企业和个人开发者难以承担这样的风险。 综上,自行搭建和托管大型语言模型虽有自主可控的优势,但其背后的技术复杂性、庞大投入、安全风险及运营压力无疑为普通用户树立了高门槛。借助成熟的云端AI平台,不仅能够享受高质量的模型资源和专业运维支持,还能按需付费灵活调整资源,显著降低成本与风险。
未来,随着AI市场的不断成熟与规范,个人和企业将更多依赖合作共赢的生态环境,而非孤军奋战的自行托管。 因此,如果您正考虑自行托管大型语言模型,建议三思而后行。关注自身实际需求,理性评估团队能力与资金状况,选择合适的AI服务方案。通过合理利用行业领先的云端AI平台,您不仅能快速获得高效智能的应用体验,还能将更多精力投入到创新和业务拓展中,从而实现智能化转型的最大价值。切记,在AI时代,谨慎规划与科学决策才是引领未来的关键。 。