随着人工智能技术的迅猛发展,大型语言模型(LLM)在自然语言处理领域的应用日益广泛,跨界赋能了从内容创作到代码生成等各个领域。然而,模型背后的血统和训练数据源的复杂性也日益成为行业关注的焦点。正因如此,如何准确判定一个语言模型的祖先关系,即模型的“家族谱系”,逐渐成为研究热点。其中,名为“Slop Forensics”的创新技术凭借其独特的分析方法,为揭示模型的起源和演进提供了全新的视角。Slop Forensics技术的核心在于“slop配置”的创建和比对。所谓slop,指的不是字面意义上的混乱或错误,而是在模型输出文本中反复出现的特定词汇、短语及写作模式。
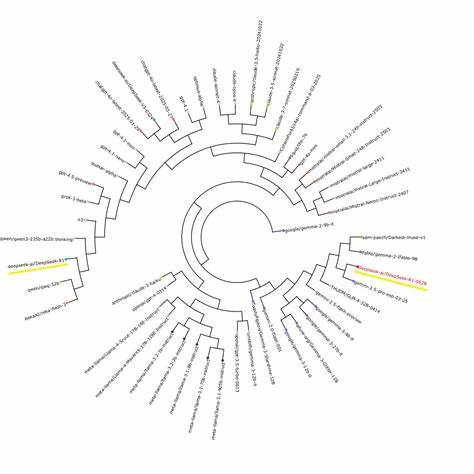
通过采集和分析模型在生成创意文本时的频繁用语和独特表达,Slop Forensics能构建每个模型的专有“指纹”。这种指纹依据模型生成内容中的特征序列进行量化,形成独一无二的“slop配置文件”。随后,研究人员利用类似生物信息学中构建进化树的算法,通过比较这些配置文件的相似度,推断模型间的亲缘关系和发展路径。这种类比生物学进化的方法,让复杂的模型族谱变得可视化和可理解。EQ-Bench项目由AI研究员Sam Paech主导,创造了Slop Forensics的完整流程与实践平台。该平台不仅可以实时生成多款语言模型的slop配置,还允许用户查看和比对不同模型之间的slop相似度及其暗含的血缘关系。
EQ-Bench的界面设计简洁友好,用户只需点击特定得分旁的“i”图标,即可获得详尽的slop配置分析报告。以近期广受关注的DeekSeek R1模型为例,Slop Forensics揭露了DeekSeek模型近乎戏剧性的转变——其训练数据来源从OpenAI系列模型切换到了谷歌的Gemini系列。这一转变不仅在slop配置中表现为明显的相似度跃迁,还导致模型风格、用词偏好乃至创作内容的整体调性发生微妙变化,令DeekSeek的输出更接近谷歌家族LLM的特征。这一案例生动说明了Slop Forensics在追踪模型血统和揭示训练数据依赖方面的巨大潜力。值得关注的是,随着合成数据使用的普及和多模型协同开发的趋势,Slop Forensics技术揭示了一个行业内鲜有探讨但不容忽视的问题:模型间的风格趋同和创新性下降。当不同企业或团队反复利用相同或高度相似的基础模型生成数据,这种“数据污染”导致模型输出中独特性词汇和表达的共享,最终形成了模型之间的高度相似slop配置。
这种趋同效应在创意写作、虚构文学等非事实性文本的生成中尤为突出。例如多个模型开始普遍使用特定的虚构人物名字“Elara”,体现出一种潜移默化的文化统一趋势。虽然这有助于提高语言模型产出的连贯性和稳定性,但对于追求多样性和创新性的研究者及应用者来说,无疑是一个挑战。在更广泛的角度看,Slop Forensics不仅是一个技术检测工具,更是促进人工智能生态健康发展的关键助力。它为合成数据的透明化和责任归属提供了可能,有助于防止因数据泄漏、版权争议或模型盗用引发的法律和伦理问题。同时,对于模型开发团队而言,利用这种方法可以精准评估自身模型在市场中的独特定位、优化训练数据结构,以及预测未来模型演化趋势。
随着人工智能模型规模和复杂度不断攀升,单靠传统的训练记录和架构说明已难以全面捕捉模型发展轨迹。Slop Forensics的引入,是突破这一困境的重要尝试。未来,结合更多维度的模型行为特征分析与黑盒测试,Slop取证技术有望在行业监管、模型评估与创新保护等领域发挥更深远的影响。同时,业界也呼吁构建标准化的slop配置和血统分析框架,推动这一技术从实验室走向产业落地。总体而言,Slop Forensics代表了人工智能发展史上的一次重要进展。它不仅打破了传统模型研发信息壁垒,也为推动模型多样性和创新注入了新动力。
在人机协作日益紧密、内容生成智能化不断提升的趋势下,深入理解和运用Slop取证技术,将成为塑造未来AI语言模型生态的关键一步。