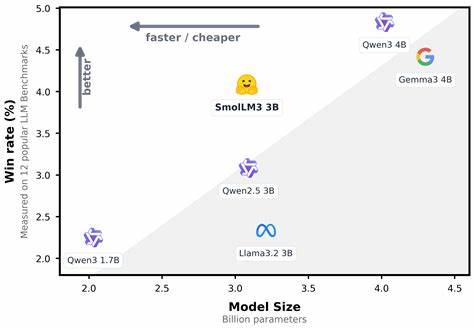
随着人工智能领域的不断发展,语言模型的规模、性能以及应用场景需求日渐多样化,小体量模型因其高效灵活性越来越受到重视。SmolLM3作为一款出色的3B参数量级多语种长上下文推理大型语言模型,体现了这一趋势下的创新力量。它不仅在性能上超越同规模同类模型,更借助多项技术优化,赋予了长达128k上下文的推理能力,极大地丰富了语言理解和应用的广度与深度。SmolLM3的发布不仅仅是一个模型的面世,更是开源社区在高效多语种智能处理领域迈出的坚实步伐。SmolLM3基于变换器(Transformer)解码器架构,结合了多项先进技术,优化了算力消耗与推理效率。它采用分组查询注意力机制(Grouped Query Attention,GQA),通过将多头注意力划分为四组,有效地减少了键值缓存的规模,从而提升了推理阶段的存储效率同时保证性能。
相比传统多头注意力,GQA在保持模型表现的同时,实现了显著资源节省,成为SmolLM3架构亮点之一。在位置编码方面,SmolLM3引入了NoPE(No Positional Embeddings)策略,以《RoPE到NoRoPE及其迂回》的论文为技术基础,选择性地在每四层中去除旋转位置编码。此举有效增强了模型处理长序列时的稳定性与精度平衡,突破了纯旋转位置编码在长上下文推理中的限制,使模型能够既保持短文本表现,又显著提升长文本推理能力。针对训练过程中的块级文档遮蔽(Intra-Document Masking)机制,是SmolLM3确保长上下文训练稳定性和准确性的关键。通过训练阶段避开序列中不同文档间的相互干扰,模型在面对多文档长文本时,能够更专注于单文档关联语义,减少噪音影响,保证推理和理解的连贯性和准确性。SmolLM3训练过程分为三个主阶段,系统混合使用网页、数学和代码数据,历经11.2万亿标记的大规模训练数据沉淀。
第一阶段奠定模型基础,注重多样化网页语料,占比高达85%;代码与数学分别占据12%与3%。第二阶段调整数据比例,注入更多高质数学和代码数据,不断完善模型在推理和技术领域的表现。第三阶段进一步上采样数学与代码语料,强调推理能力的培养,特别加入了OpenMathReasoning等推理专用数据集,增强模型对复杂问题的逻辑判断能力。除了基础大规模预训练,SmolLM3还有专门的中期训练(Mid-training)环节,聚焦于长上下文扩展和推理能力提升。通过另外1000亿tokens的训练,模型从4k上下文顺利迁移至可处理64k上下文,再运用YaRN技术,在推断期间触达128k的上下文长度,为长文档处理和复杂对话提供了技术保障。此外,中期推理训练阶段,利用公开的推理数据集进行泛化推理能力的训练,使模型能够适应多样化、跨领域的推理任务,提升了模型的灵活性与智能推断能力。
SmolLM3另一个创新点是其双模式指令微调技术,允许用户灵活切换推理模式(/think)和非推理模式(/no_think),满足不同应用场景对推理深度和响应速度的需求。训练时通过合成数据增强推理轨迹,提高模型在多语种、多轮会话及代码和数学领域的实用性。为保障模型行为的对齐性和质量,SmolLM3采用Anchored Preference Optimization(APO)进行离策略模型对齐,提升生成内容的遵循度、准确性及人类偏好契合度。相较于传统的DPO,APO提供了更稳定的优化目标,使得模型在多轮任务中表现更加均衡。此外,针对推理训练对长上下文性能带来的影响,团队采用模型融合技术,结合推理细化阶段和长上下文中期训练的优势,成功恢复并强化了模型在长序列处理中的表现,使模型在保持推理强度的同时,不牺牲其文档理解能力。SmolLM3支持多语种应用,涵盖了英语、法语、西班牙语、德语、意大利语和葡萄牙语六种主要欧洲语言。
其多语种tokenizer基于LLaMA 3.2的设计,采用了高达128K词汇表,通过整合部分非英语语言特有的tokens,保证了跨语言文本的高效压缩率和信息表达能力,体现了其多语言环境下稳定高效的文本处理表现。模型评测覆盖了知识理解、常识推理、数学推算、代码生成等多项任务,在HellaSwag、ARC、BoolQ、GSM8K、HumanEval+等权威基准测试中均取得优异排名。尤其在数学推理和复杂推理任务中,相较同类3B模型展现出显著领先,同时于多语种任务中完成稳定表现,验证了其多领域全方位能力。实用层面,SmolLM3兼容主流机器学习框架,集成于transformers库和vllm推理引擎,方便开发者进行模型加载与应用。支持长达128k上下文令牌的生成,默认开启的推理模式/思考模式提升生成解释的详实度和逻辑性,且可随时通过系统提示切换推理状态以满足不同的推理深度需求。此外,模型原生支持工具调用功能,能够灵活处理标准XML格式工具及Python代码片段工具调用,为多任务、多模态场景拓展打下坚实基础。
对于本地运行,用户根据GPU或CPU环境安装相应依赖后,即可体验SmolLM3提供的高效推理和广泛多语种支持。鉴于其设计上的高效性和精巧的训练流程,SmolLM3在算力有限的条件下,依然可发挥出与更大参数模型相媲美的性能,为广大科研人员、工程师和终端用户提供了理想选择。总体而言,SmolLM3是当前小型多语种长上下文推理语言模型领域的里程碑之作。它不仅体现了通过架构创新、训练策略提升、数据精选和后期微调协同发展的工程智慧,也为未来轻量级智能模型的发展路线提供了宝贵参考。未来,SmolLM3的开源化和详细训练配方的发布,必将促进更多创新模型的涌现,推动自然语言处理技术向更高效、更智能和更实用的方向演进。随着人工智能的广泛普及和多语言智能需求的升级,SmolLM3将为智能对话系统、专业推理问答、多语种内容生成等领域提供强大支撑,助力实现真正多场景、多语言的智能服务。
。