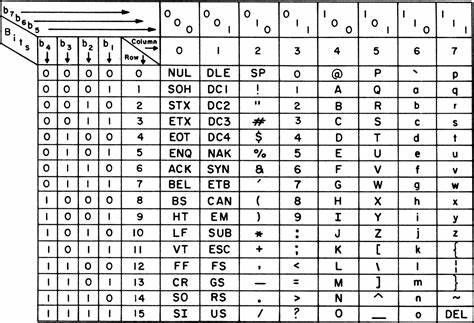
在现代数字化时代,排序作为信息处理的基础操作之一,似乎是一项简单且理所当然的任务。许多人认为,排序不过是将字符按照其编码顺序排列,比如大家熟悉的ASCII码表中的字母顺序。然而,现实远没有这么简单。排序不仅仅是字母表的排列,更涉及不同语言和文化中复杂且细致的规则,这些规则统称为"排序规则"或"校对(collation)"。本文将深度解析为什么简单的ASCII排序不能代表真实的语言排序,以及如何理解和实现更精准的排序方法,特别是数据库系统中复杂的排序问题和解决方案。首先,简单了解ASCII排序的局限性非常重要。
ASCII码表是一种字符编码标准,它按照一定数值给每个字符分配编码。例如,大写字母A对应65,小写字母a对应97。按此顺序排序,所有大写字母会排在小写字母之前,且排序纯粹基于数字的大小。然而,现实中人们的阅读习惯和语言规则却往往不接受这种顺序。举个例子,在手工制作的索引或者字典中,大写B和小写b通常不会混合排列,而是以统一的字母顺序出现,忽略大小写差异。更复杂的是,包含特殊字符、音调符号以及不同书写系统的语言,排序的规则更加复杂。
ASCII排序无法识别重音符号的区别、不同字母变体以及文化专有的排序习惯。例如,法语中对于包含重音的字母排序规则明显区别于简单的ASCII字母序列。法国本土法语和加拿大法语甚至在处理重音的顺序上存在差异,这种区域性差异显示了排序规则的复杂多样。除了简单的字母和大小写之外,排序还必须考虑音调、变音和标点符号,这些被称为"排序强度"的不同层次。在校对理论中,通常存在初级(primary)、次级(secondary)和三级(tertiary)不同的比较强度。初级比较仅考虑基础字母,比如A与B;次级比较包括重音和变音符号,如e和é的区别;三级比较涉及大小写和特殊书写形式。
例如,"a"和"A"在初级比较中被视为相同,而在三级比较中则不同。不同语言根据具体需求,可能会加重某个层级的重要性,甚至引入更多复杂的规则。比较复杂的语言如德语和西班牙语存在多字母组成的单个"字母",例如德语中的"ß"相当于"ss",西班牙语中"ñ"的排序也具有特殊的优先级。此外,一些语言如韩语的排序是以音节为基本单位,而非单个字母,这与ASCII编码完全不相关,使得简单的字节比较毫无意义。数据库系统在处理字符排序时面临巨大挑战。传统的字符串比较方法往往基于字节或Unicode代码点的顺序,一旦涉及多语言支持、区分大小写和重音的准确比较,这些方法显得极为不足。
以MySQL为例,其默认的排序方式在处理Unicode字符时并不完全符合国际通用的Unicode排序算法(UCA),存在对"组合字符"(如带重音的字符与分离的基字符加重音符号的组合)处理不当的问题。Unicode中的同一字符可以存在多种编码形式,但理想排序应视其为相同字符。MySQL未完全遵循这一规则,导致类似"é"和"e+重音符"的字符在排序和比较时出现不一致。Readyset作为现代数据库性能优化解决方案,也直面传统排序机制的局限。早期版本仅依赖Rust语言默认的字节比较,无法满足准确的语言环境排序需求。为了解决这个问题,Readyset选择了ICU4X这款由Rust实现的新一代Unicode排序库。
ICU(国际Unicode组件)是一套广泛应用于多语言文本处理的跨平台库,而ICU4X是对其功能的现代化重写,强调效率和灵活性。ICU4X不仅遵循Unicode排序算法,还支持生成"排序键",这是一种用于加速排序和哈希的字节序列,使字符串的排序与其对应的排序键的字节顺序保持一致。排序键极大提高了多语言数据库的查询速度,同时确保排序正确性。在实现过程中,Readyset团队还向开源社区贡献了关键代码,解决了ICU4X在排序键生成方面的缺陷,从而推动了整个社区的进步。真正准确的排序系统能够灵活处理不同语言、不同地区的排序习惯,包括复杂的多字母组合和大小写差异。例如,法语就有不同地区对重音的考虑顺序,德国对"ß"和"ss"的处理与传统字节比较截然不同。
这种多样性要求排序算法具备高度的可定制性和规范性。未来,随着全球化和多语言数据处理需求不断增长,排序的复杂性只会增加。企业和开发者必须意识到简单的ASCII码排序远远不能满足实际需求,必须采用符合Unicode标准的校对算法,甚至针对特定语言或地区定制排序规则。同时,数据库和应用软件需集成先进的排序库,利用排序键技术以兼顾性能与准确性。总之,排序远非简单的字符编码顺序比较。真实排序反映了丰富的语言文化信息和复杂的文本处理需求。
理解排序规则的多层次属性、语言差异及技术实现,是打造国际化、高效且准确数据系统的关键。通过采用现代的Unicode排序标准和技术,开发者能够提供更加符合用户期望的排序体验,推动软件与数据库处理迈向更加智能和精准的未来。 。