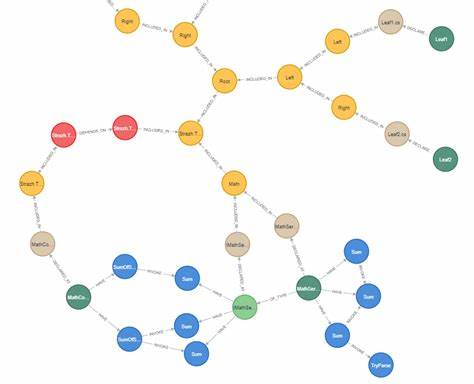
随着软件开发规模和复杂性的不断提升,代码库的管理与理解成为了工程师们面临的重要挑战。传统的代码浏览和分析手段在面对多语言和巨量代码时,往往力不从心,难以实现代码结构的全面把控和快速定位。基于图谱的代码库理解技术应运而生,它通过构建代码的知识图谱,将代码元素和它们之间的关系以图结构呈现,极大地提升了代码探索、查询和优化的效率。Graph-Code正是这样一款前沿的图谱驱动代码理解系统,它结合了先进的抽象语法树解析、多语言支持和人工智能技术,打造出适合现代复杂代码库管理的智能工具体系。Graph-Code通过利用Tree-sitter作为多语言的语法分析器,具备强大的跨语言解析能力。Tree-sitter支持Python、JavaScript、TypeScript、C++、Rust、Java等多种编程语言,能够精准地提取函数、类、方法、模块等代码结构信息。
基于这些结构信息,系统将代码构成的元素以节点形式存储在Memgraph图数据库中,节点之间的调用关系、包含关系等则通过边进行连接。这种图数据库的存储方式使得代码库结构的查询更为灵活,支持自然语言形式的问题询问,如查找某类函数、探索特定类的方法,或是分析模块间依赖。Graph-Code系统还集成了强大的AI驱动查询能力,用户可以采用多种模型如Google Gemini、OpenAI、或本地模型Ollama,辅助将自然语言请求转换为图查询语句(Cypher),极大简化了复杂查询的门槛与操作难度。系统的交互CLI让开发者可以以对话式体验探索整个代码库,定位代码片段,甚至能够检索具体实现代码段,满足日常开发或代码审查的需求。除了代码浏览与查询,Graph-Code的一个显著优势是其支持精准、智能的代码修改能力。通过基于AST的精细代码块定位与替换,系统可完成“手术式”的代码编辑,只修改目标函数或类的代码,而不影响上下文,确保改动安全可靠。
用户在修改前可通过可视化差异预览,增强对修改影响的理解。这一功能对于代码重构、功能增强及修复bug等场景尤为关键,提升了代码维护的效率与质量。另一大亮点是Graph-Code提供了基于AI的代码优化模块,能够结合项目的代码结构和参考文档(如团队编码标准、架构指南)给出语言特定的优化建议。优化过程注重交互,开发者可以选择接受或拒绝每条建议,确保优化与项目需求契合。这不仅帮助开发者改进性能和代码整洁度,也推动团队编码规范落实。Graph-Code引入了对多语言复杂特性的全面支持。
无论是Python的装饰器与嵌套函数,JavaScript的箭头函数和ES6模块,C++的模板和操作符重载,还是Rust的impl块和枚举,系统均能正确解析并建立对应的图谱节点及关系结构。同时还支持Go、Scala和逐步加入的C#等语言,使得跨语言大型代码库管理成为可能。对于那些语言缺失或尚处于开发中的支持,Graph-Code系统提供了简易的扩展机制,用户可以借助Tree-sitter语法定义,快速添加对新语言的图谱解析支持,确保工具的持续演进和适应性。图谱驱动模型的另一个不可忽视的优势是支持导出完整的图数据为JSON格式,方便第二次开发、自动化分析及结合其他工具链,比如生成代码文档、建立代码指标仪表板、或进行依赖关系分析。这样的开放性设计有效突破了传统大语言模型接口的限制,确保数据的所有权和灵活使用。从技术基础设施角度来看,Graph-Code依赖的组件包括Tree-sitter的强大解析能力,Memgraph高性能的图数据库,以及灵活的AI模型调用接口。
开发环境使用Python 3.12+并借助Docker容器简化了部署。丰富的命令行操作支持全流程管理,从代码解析、知识图谱构建、自然语言查询,到高级的代码优化与编辑,形成闭环作业流程。Graph-Code的设计充分考虑了安全与可靠性,编辑功能实施文件系统沙箱限制,禁止对项目目录外文件的写操作,保护项目完整性。此外,通过精准的AST定位和智能函数匹配,有效避免了误修改和潜在风险。面向未来,基于图谱的代码库理解正在成为软件开发数字化转型的重要推动力。随着AI能力的不断增强,图谱中蕴含的代码语义将被更深层次地利用,开启自动化重构、智能代码生成、甚至跨语言迁移等更高级应用。
Graph-Code的开放架构和跨语言覆盖将使其在多样化项目中得到更广泛应用,并助力团队实现效率飞跃。总结而言,Graph-Code代表了图谱驱动代码理解技术的前沿成果。它融合多语言静态分析、图数据库存储和AI智能交互,为开发者提供了强大而灵活的工具,极大提升了代码浏览理解、查询优化和精细编辑的能力。对于需要同时管理多个语言、多层级复杂依赖的现代软件项目,Graph-Code提供了一种系统化、智能化的解决思路。不论是提升代码可维护性、优化开发流程,还是支持规范驱动的持续改进,图谱技术和AI赋能的结合,必将在未来软件工程领域发挥日益核心的作用。