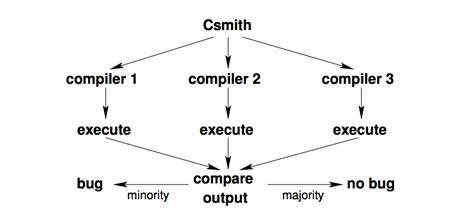
在软件开发过程中,编译器扮演着至关重要的角色。作为连接程序源代码和机器指令的桥梁,C语言编译器的准确性直接影响着最终程序的运行效果和性能表现。然而,尽管编译理论不断发展,实际的编译器实现依旧存在不可忽视的错误风险。编译器错误不仅会导致程序异常崩溃,更可能生成错误的机器代码,这种错误往往在运行时难以察觉甚至造成严重的安全隐患。发现和理解这些错误对于保证软件质量具有深远的意义。长期以来,凭借固化的测试用例对编译器进行验证是一种常见做法,但这种方法在发现未知或复杂错误方面存在局限。
针对这类问题,近些年兴起的随机测试技术提供了一种革新性的解决方案。特别是由犹他大学开发的Csmith工具,通过自动生成大量语法正确且无未定义行为的随机C程序,为检测编译器中的缺陷带来了全新思路。Csmith生成的测试程序覆盖了C语言的多种复杂特性,保证了程序具有唯一的语义解释,从而避免由于标准未明确定义行为引起的误判。这种差异测试的思路基于将同一测试程序用多个编译器或相同编译器的不同版本进行编译执行,通过比对输出结果来识别潜在缺陷。经过多年的应用实践,Csmith在GCC、LLVM等主流开源编译器以及多款商用编译器中发现了超过325个未知错误,其中包括导致编译器崩溃和静默生成错误代码的问题。值得注意的是,其中约有25个错误被标记为GCC最高优先级的关键缺陷,显示出该方法在实际项目中的重要价值。
事实上,编译器错误主要来源于代码优化和转换中的逻辑漏洞。优化过程往往涉及多个安全检查和静态分析环节,未能完全考虑某些边界条件或罕见的语言特性组合时,容易引发错误的代码生成。此外,编译器内部的模块设计、代码复杂度以及支持众多不同体系结构的需求,也增加了出错的风险。传统的手工测试方法无法覆盖所有潜在场景,对于不常见或意外的语言用法缺乏充分测试,导致错误被忽视。为了解决这一挑战,Csmith采取了多项创新设计。它不仅随机生成代码结构复杂多样的C程序,还利用静态分析手段剔除所有含有未定义或未指定行为的代码路径,保证每个测试程序的合法性和确定性。
测试中集合使用多个编译器版本,通过差异检测自动定位错误,显著提高了错误发现效率。通过大规模测试,Csmith还提供了丰富的量化数据分析。例如,测试显示较大规模的测试用例更容易触发编译器错误,反映出复杂程序组合对编译器的压力明显增加。同时,通过覆盖度分析发现随机生成的程序能够探索编译器代码中鲜有触达的路径,弥补了传统测试的不足。此外,案例研究揭示了某些错误隐蔽性极强,仅在特定代码结构和编译选项组合下出现,这进一步证明了自动化、广泛且多样化测试的重要性。在实际应用中,开发者和研究人员已经开始将Csmith集成到编译器开发和回归测试流程中。
它不仅帮助发现新错误,还验证了已有缺陷修复的有效性,有助于持续提升编译器的稳定性和正确性。另一方面,Csmith的成功经验也启发了其它编译器和程序分析领域采用基于随机生成的测试技术。尽管如此,对于编译器测试和错误分析依然存在一定的挑战。首先,编译器本身的复杂性和不断变化的语言标准使得测试工具需要不断更新以保持适用性。其次,错误定位和修复仍需借助专家深厚的知识和经验,自动化程度有限。此外,部分编译器针对安全和性能进行了高度定制化优化,误判和噪声数据时有出现,增加了解释测试结果的难度。
未来,结合程序验证技术、机器学习辅助诊断方法以及更智能的测试用例生成,可以进一步提升对编译器缺陷的检测和理解能力。总的来看,发现并深入理解C语言编译器中的错误,是保障软件系统可靠性不可或缺的环节。Csmith等工具通过随机生成测试程序,推动了编译器测试领域的革新,显著提升了错误检测效率和覆盖率。与此同时,持续积累的错误数据和案例分析,也为编译器设计者提供了重要的经验指导。随着技术不断进步,结合多种方法的综合测试体系有望进一步确保编译器质量,让广大程序员和终端用户享受到更加安全稳定的软件产品。