在现代软件开发中,Git已经成为不可或缺的版本控制工具。无论是个人项目还是大型开源项目,Git都以其强大的分布式管理和高效的版本追踪赢得了广大开发者的青睐。然而,尽管Git已经广泛使用,许多使用者对于Git的内部机制仍存在误解,其中最容易混淆的概念之一就是Git提交(commit)与Git树(tree)的区别。理解这两者的本质差异,不仅能帮助开发者更好地应对复杂的代码管理场景,还能优化仓库的使用效率。本文将深入探讨Git提交与Git树的区别,揭示Git的底层工作原理,助力开发者提升对Git的认知深度。 Git作为一种内容可寻址存储系统,实际上是通过哈希值(SHA1或SHA256等)链接不同的对象实现版本管理的。
每个Git对象都有唯一的哈希值标识,这些对象主要包括提交对象(commit)、树对象(tree)、以及文件内容对象(blob)。在这些对象中,提交对象和树对象的关系是理解Git架构的关键。提交对象相当于版本的快照记录,而树对象则用于表示项目目录的文件结构。 首先,Git提交对象并不直接包含项目文件的具体内容,而是包含指向树对象的引用。树对象则细致地描述了某一项目快照时刻的目录结构和文件内容的哈希值。换而言之,提交对象是对整个项目状态的元信息快照,它记录了提交的作者、提交信息、时间戳和一个指向项目文件结构(树对象)的指针。
树对象内部则是更底层的文件和目录索引,它将文件的blob对象和子树组织起来,呈现一个完整的文件系统快照。 这种设计使得Git在处理代码历史时极具优势。例如,假如开发者在多个提交之间只修改了部分文件,那么相应的blob和树对象仅在变动处发生更改,而未变更的文件内容和树对象会被重复引用。这不仅节约了存储空间,还提高了Git操作的效率,因为Git避免了无谓的文件复制。换句话说,不同提交虽然拥有不同的提交id(commit hash),但大部分树对象和文件内容却可能是共享的。 一个现实案例能够清楚展示这一点。
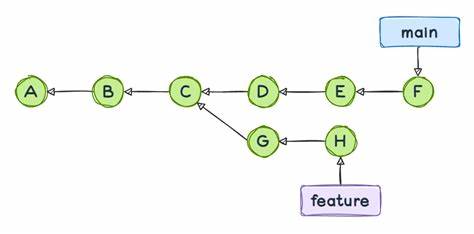
随着Firefox项目于2025年将其官方源代码仓库迁移到全新Git仓库,许多开发者面临着因为提交历史完全不同而不得不重新克隆整个仓库的烦恼。尽管新旧提交的哈希值不同,实际上大部分源代码文件内容和目录结构并未发生改变。由于Git树对象和blob对象在两者间高度重合,技术上可以通过在已有仓库添加新仓库为远程源,使用pull操作智能地只拉取不同的提交对象,以避免重复下载冗余数据。这一技巧能够极大减少带宽消耗和克隆时间。 了解这一点有助于更灵活地管理Git仓库,特别是涉及大规模项目迁移、历史重写或多重仓库协作时。因为Git提交与树对象的分离设计,使得版本历史的更新不限于对所有内容的完全替换,而是只针对提交层面进行调整。
开发者可以通过这一机制进行历史重写(如通过git rebase操作),在不重复下载文件内容的情况下,实现在新的提交序列基础上保留实际代码文件。 此外,这种设计也为备份和数据完整性提供了强有力保障。将文件系统快照分层存储,一定程度上防止了数据冗余,并且所有对象的内容都基于哈希校验,确保数据不可篡改和被高效验证。在分布式环境中,每个仓库节点保持相同对象的指向一致性,有效减少冲突和合并复杂度。同时,Git的这种架构也使得开发者能够轻松实现代码回滚和版本恢复,针对特定的树对象即可快速还原对应版本文件结构。 值得注意的是,对于初学者而言,混淆提交与树对象可能导致误解Git操作效果。
例如,一些用户错误地认为每次提交都等价于一次全量文件拷贝,实际上Git通过引用未变更的树对象和blob,大大优化了存储和性能。理解了历史提交和树的关系后,开发者就能更合理地解释和预测Git操作结果,提升版本控制的掌控力。 总结来看,Git提交与Git树的关系体现了Git设计的精妙与高效。提交对象作为版本快照的元信息载体,仅仅是指向具体文件目录状态的树对象,而树对象记录了文件系统的详细内容和层级结构。分辨这两者清晰界线,有助于优化仓库管理,提升数据传输效率,促进团队协作,并加深对Git内部工作机制的理解。对于开发者而言,掌握Git提交与树的区别,既是进阶Git技能的必由之路,也是迈向高效代码管理的关键一步。
未来随着版本控制需求的不断提升,深入理解Git的内容寻址存储和提交树分离结构,必将在实际开发工作中带来更大的便利与价值。