引言 在生成式AI和大规模语言模型急速扩张的背景下,注意力层(attention)的计算性能已成为能源和成本的核心瓶颈。Flash Attention 系列自问世以来以高效的内存与计算管理著称,而最新的Flash Attention 4(简称FA4)针对NVIDIA Blackwell系列SM(Streaming Multiprocessor)做出了深度优化,带来了可观的吞吐提升。本文从工程与架构视角出发,剖析FA4的关键设计思想、实现细节与若干数学技巧,帮助工程师理解为何它在实际推理中表现优异,以及这些优化对未来GPU编程的启示。 为什么Flash Attention 4重要 大规模Transformer模型的注意力计算本质上需要海量的矩阵乘法、指数运算与归一化操作。单纯依赖通用矩阵乘法或逐元素操作会导致内存访问频繁、算力无法充分利用、并发不足或硬件资源发生争用。FA4通过在Tile(块)粒度上重构计算流程、利用Tensor Core和程序员可控的共享内存(shared memory)与Tensor Memory,搭配warp级别的专门化与异步流水线,将算力与内存带宽利用率推到更高水平,从而实现相比传统cuDNN attention核显著的性能提升。
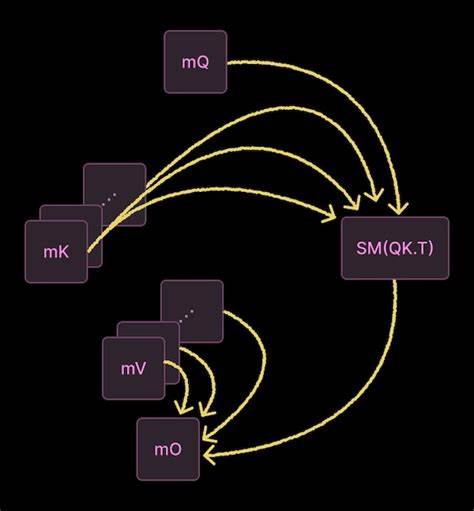
整体架构与"Tile 的生命周期" FA4采用分块(tiling)策略,把大矩阵分割为相邻的行列块。每个核实例(CTA,cooperative thread array)负责处理两块输出tile,沿途流式读取对应的query、key与value块。关键在于在单个CTA内部建立多阶段的异步流水线:Load、MMA(矩阵乘加)、Softmax、Correction与Epilogue等不同功能由专门的warp承担,形成生产者/消费者关系并通过共享内存和屏障同步传递数据。这种设计让不同阶段可以高度并发地推进,借助warp切换(warp scheduling)隐藏延迟并提升硬件利用率。 在内存层级上,FA4以全局内存为源端,先将query块加载到共享内存,再循环流式加载key/value块。MMA阶段调用Tensor Core将query与key相乘产生未归一化的attention分数(S),这些中间结果被保存到Tensor Memory,以便后续由Softmax与Correction阶段读取并归一化。
最终,经过加权累加的输出在Epilogue阶段写回全局内存。整个过程中,多重缓冲(double/triple buffering)被用来保持Load与计算并行,从而达到高并发吞吐。 Warp 专门化与异步流水线 FA4将任务按功能划分给不同warp:Load负责异步拷贝并通知后续阶段;MMA在Tensor Core上完成关键的矩阵运算并在Tensor Memory上累加结果;Softmax用若干warp实现在线归一化与指数运算;Correction负责在数值缩放因子变化时对已产生的结果进行补正;Epilogue将最终结果打包写出。这样的warp专门化配合共享内存中的显式屏障同步,使得单个CTA内部形成一个细粒度、可并发推进的流水线。 相比于以往更偏向"单线程完成全部阶段"的实现,FA4的这种设计更像是微服务架构:各阶段职责分明,各自优化并以高速通道传递数据。GPU的warp调度器在时钟级别切换活跃warp,从而让计算单元保持高利用率。
需要注意的是,这种异步与手工调度带来了编程复杂度的显著上升,但在性能上回报丰厚。 关键实现技术 FA4在多个层面做了工程与数学上的折衷与创新,值得细细拆解。 Tensor Memory与Tensor Core协同 Tensor Memory是Blackwell为Tensor Core设计的一个可由程序员管理的L1缓存,专门用于存放Tensor Core间的累加中间量。MMA warp直接在Tensor Memory上累积S与O(未归一化分数与输出累加)以避免频繁往返全局内存。实现上,MMA的矩阵乘加通过内联PTX指令发出,具体为tcgen05.mma指令,该指令映射到Blackwell第五代Tensor Core。和传统的warpgroup跨多个CTA/SM的做法不同,FA4在很多实现路径上只以单个CTA或单个warp为单位发起MMA,从而简化调度与同步逻辑,虽然可能带来少量内存吞吐权衡。
TMA(Tensor Memory Accelerator)用于降压寄存器压力与异步复制 Load阶段使用TMA异步传输数据到共享内存,这减少了长时间的warp停顿并降低了寄存器占用。借助TMA,Load可以预取多块K与V数据(最多支持三块缓冲),并在后台完成拷贝,随后通过共享内存屏障通知MMA或Softmax开始处理。这种生产者/消费者的并发模型使得计算与内存操作能够有效重叠。 在线Softmax与数值稳定性改进 Softmax的实现要同时满足性能和数值稳定性。传统做法往往对每行先做一次扫描以找到最大值,但这会破坏流式处理的优势。Flash Attention家族采用在线softmax算法:在流式处理分数时维护running max与running sum,用以做数值缩放和归一化。
FA4在此基础上引入了更智能的缩放更新策略:只有在新观察到的最大值增长到足以威胁数值稳定性的阈值时才触发对已计算输出的修正(correction),从而把昂贵的重新缩放次数减少约一个数量级。这一优化既能保证稳定性,也能显著降低Correction阶段的工作量。 近似指数计算以缓解SFU瓶颈 传统实现多依赖GPU的特殊函数单元(SFU)执行exp2等指数操作,但SFU数量远少于通用CUDA核心,容易形成队列延迟。FA4采用了一种混合策略:在某些迭代与较小Head尺寸下,用一种快速的多项式近似代替SFU计算。该方法把2^x分为整数幂与小数部分两段,将小数部分在[0,1)区间内用三次多项式近似,并通过Horner法用三个fma指令进行高效计算。这种近似在bf16精度下与硬件SFU输出匹配良好,同时在整体吞吐上避免了SFU的串行化成为瓶颈。
为了兼顾精度,近似并不总是使用,且在最后若干tile上会禁用,从而降低累积误差风险。 PTX内联与低级优化 要在Blackwell上利用最新的Tensor Core与指令,FA4在关键路径大量使用内联PTX和直接调用tcgen05.mma等底层指令。虽然这让代码可读性和移植性变差,但却能获得最高的性能。工程上也必须在寄存器占用、共享内存布局、warp分配和屏障数量之间做权衡以避免资源争抢。 调度策略与TileScheduler FA4通过TileScheduler把任务映射到SM与CTA。StaticPersistentTileScheduler是高性能配置的首选,它会在每个SM启动不超过一个CTA,并对tile在持久CTA之间做细粒度调度,从而避免频繁的CTA启动开销并允许更灵活的并发(例如让Epilogue与下一tile的Load并行)。
这种持久化调度在实际峰值性能上有明显优势,但对实现复杂度提出了更高要求。 性能与权衡 在Blackwell上,FA4相较于上一代实现(例如cuDNN attention核或FA3)报告了约20%的平均性能提升。性能收益来源包括更低的内存访问开销、更高的Tensor Core利用率、更少的SFU拥堵和更精细的数值修正策略。权衡点在于实现复杂度显著上升、代码对底层硬件细节的依赖更强,以及可维护性与移植性的下降。内联PTX与专用硬件指令带来了最高性能,但也使得对未来架构变化的适应成本更高。 对GPU编程未来的启示 FA4的设计体现了当前GPU编程的两个重要趋势:程序员可控的异步与细粒度并发,以及在低级指令层面对硬件特性的深度适配。
未来的优化将越来越依赖于在硬件特性(如Tensor Memory、TMA、warp调度拓扑)之上构建复杂流水线,而不是仅依赖编译器与库的自动化变换。为应对编程复杂度,生态中已经出现诸如Gluon前端、CuTe、CUTLASS与更高层的DSL,这些工具试图在抽象与性能之间找到更好的平衡。 结语 Flash Attention 4展示了如何在Blackwell等新一代GPU上通过系统性的工程优化实现显著的推理加速。关键在于将计算分片为可并发的流水线阶段、精细管理不同内存层级、用近似数学方法缓解硬件瓶颈,以及在必要时下沉到PTX级别获取性能极限。对于从事高性能深度学习推理的工程团队而言,理解FA4的设计理念既有助于评估第三方实现,也能启发在自研推理引擎中如何在性能与复杂度之间做更智慧的权衡。随着硬件架构继续演进,像FA4这样的工程探索将继续推动大模型推理的效率上限,同时也对软件抽象与工具链提出了更高的要求。
。