随着人工智能技术的飞速发展,图像生成领域迎来了革命性的变革。尤其是在角色设计和数字艺术创作中,实现角色一致性的图像生成成为业界和创作者的关注重点。传统的多视角或多样本训练往往资源耗费巨大,如何通过单张参考图像生成高质量且在多场景下保持一致性的角色图像,成为技术发展的一个重要方向。本文将深入探讨基于单一参考图像生成角色一致性图像技术的原理、流程、应用及其未来发展趋势。 角色一致性图像生成的核心挑战在于如何理解并保持角色的独特细节,包括面部特征、服饰、光影效果以及表情变化等。这些细节往往需要多角度、多表情的训练数据来辅助模型捕捉和重现,而单张参考图像则在信息维度上存在明显限制。
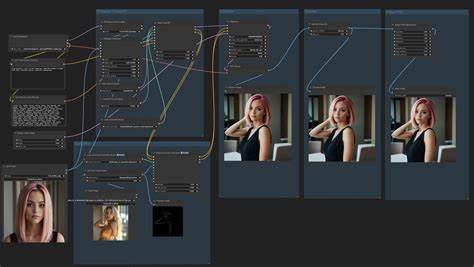
为此,现代技术引入了多种智能算法来扩充和增强数据集,提升训练模型的泛化能力,从而实现仅靠一张参考图像仍能生成多样且一致的角色形象。 当前,CharForge项目成为该领域的佼佼者,通过结合多项先进技术实现了单张参考图像训练角色LoRA的全过程。它基于ComfyUI框架,自动生成角色图像表,利用LoRACaptioner进行详细的图像自动注释,再通过高性能训练框架训练LoRA模型。生成的LoRA能够准确捕捉角色的特征,并被整合到Diffusers推理流程中,生成高分辨率、场景丰富的角色图像。 在训练阶段,系统首先根据输入的参考图像生成多视角、多光照、多表情的角色图像表,极大丰富了训练样本的多样性。此过程还包含PuLID-Flux图像的生成,进一步提升角色表情和细节的自然度。
接着,LoRACaptioner自动为生成的图像创建详尽的文字描述,确保训练数据的语义一致性和准确度。利用这些高质量的数据集,ai-toolkit进行LoRA训练,优化参数以兼顾训练速度和模型质量。 硬件方面,为了满足高分辨率和复杂模型的训练需求,推荐使用配备48GB或以上显存的 GPU,如NVIDIA L40S,搭配至少60GB内存和100GB以上的存储空间,确保训练和推理过程流畅高效。值得一提的是,初次运行训练脚本时系统会自动下载并配置所需模型和依赖,后续运行速度及效率显著提升。 在实际应用中,通过加载训练好的LoRA,可以在多种生成场景下实现角色一致性的图像输出。用户仅需输入带有角色主题的文字提示,系统便能生成符合角色特征的图像,不论是不同背景、光线还是情绪变化,都能保证角色形象的一致性和自然感。
此外,FaceEnhance技术的集成,使得面部细节更为精致,增强了生成图像的真实度。 除了为数字绘画和游戏开发带来便利,这一技术还极大地推动了影视动画、虚拟偶像、广告设计等多个领域的发展。创作者无需庞大的角色图像库,只需一张高质量的参考图像,便能快速生成海量多样、风格一致的角色图像,显著降低了时间和成本投入。 为了适应不同用户需求,CharForge还提供了丰富的高级参数设置和命令行接口,支持个性化的训练和推理配置。例如,可以调整LoRA rank、分辨率、训练步数等,灵活掌控训练过程和输出质量。此外,通过FastAPI接口布署LoRA模型,使其可供公共访问,实现云端推理和共享,拓展了应用场景和用户群体。
技术背后,CharForge依托于开源社区的积极支持,整合了ComfyUI、LoRACaptioner、MVAdapter、ai-toolkit等多个模块,实现了模块化、高效的工作流。同时,利用现代AI大模型的能力,如GPT-4o进行自动提示生成、Together AI进行图像字幕和提示优化,营造出复杂但灵活的训练与生成生态。 尽管技术不断进步,单张参考图像生成角色一致性图像仍有改进空间。例如,低质量或角度单一的参考图像可能导致训练效果不佳,光影和细节表现不足。未来结合更多智能预处理、风格迁移与超分辨率技术,将进一步提升模型对角色细节的捕捉能力。多模态融合和交互式调优也将在定制化角色生成上发挥更大作用。
综上所述,利用单张参考图像训练生成角色一致性图像,正在成为数字艺术创作的革新利器。它大幅降低数字角色设计的门槛,提高创作效率,为各类应用场景提供了强大支持。随着硬件性能的提升和算法的优化,未来该技术将更加成熟和普及,助力创作者实现更丰富、更真实的虚拟角色世界。