开放获取期刊的出现为科研成果的传播带来了前所未有的便利,学者们无需支付高额订阅费用即可自由获取最新研究成果,推动了科学知识的民主化。然而,开放获取模式也催生了大量以牟利为目的的可疑期刊,这些期刊往往缺乏严谨的同行评审和良好的编辑规范,严重危害了学术诚信。面对庞大的期刊数量和日益复杂的伪劣出版行为,传统的人工审核方式已难以满足高效识别的需求,人工智能技术因此成为研究者和学术机构关注的焦点。近年来,科学家们通过构建基于人工智能的自动化模型,尝试实现对可疑开放获取期刊的精准识别。该方法依托多个维度的特征数据,包括期刊网站的设计风格、页面内容、出版元数据以及引文和作者的学术影响力指标。通过提取这些信息,机器学习算法能够识别出潜在的不合规和低质量期刊。
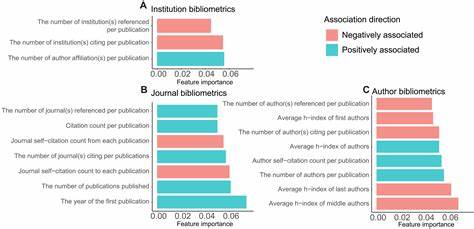
基于权威的开放获取期刊目录如DOAJ(Directory of Open Access Journals)的标准和最佳实践,研究团队将人工审核的准则转换成可供机器理解和处理的特征变量,进一步提升分类模型的解释性和透明度。研究结果显示,利用单一维度的特征难以达到理想的预测效果,而融合网站内容、设计和丰富的计量学指标则显著提升了模型的准确率和鲁棒性。计量学特征尤其重要,如期刊的首次出版年份、文章引用数、作者的h指数以及自我引用率等都在判别中起到了关键作用。基于这些数据,机器学习模型能够发现典型的可疑期刊往往是新兴的、引用较低且作者学术影响力较弱的出版平台。同时,自我引用频率过高也成为判别的一大警示信号,反映出这些期刊存在通过人为操控引用关系提升学术影响力的行为。网站设计方面,研究显示可疑期刊网站常常呈现出模板化、重复使用的设计元素,这些特征通过深度学习图像识别技术和HTML代码分析得以捕获,为判别提供了辅助依据。
在实际应用中,研究人员通过对比DOAJ收录的合法期刊与被移除的可疑期刊样本进行交叉验证,模型整体表现出较高的预测能力。此外,将训练好的模型应用于庞大的Unpaywall开放获取期刊数据库,也成功筛选出超过一千份潜在可疑期刊,涵盖了数十万篇文章和数百万次引用。值得注意的是,这些被标记的期刊涉及大量来自发展中国家的作者群体,反映了全球学术出版资源和能力的分布不均,也突显出提升研究者识别和规避可疑期刊能力的紧迫性。尽管成绩显著,人工智能模型在识别过程中依然面临挑战。部分误判案例包括因期刊名称相似或被中断出版的期刊,以及小型学会期刊因网络信息有限而难以正确分类。为了降低误判率,研究建议结合实时网页抓取技术和专家人工复核,形成机器辅助、专家主导的混合筛查体系。
此外,随着可疑期刊运营者不断调整策略,模型需持续更新和训练,以适应出版环境的动态变化。人工智能的发展为学术界提供了强有力的工具,不仅可实现对可疑期刊的系统性筛查,还能揭示隐藏在数字背后的不诚信行为模式,促进学术环境的净化。学术机构、资助机构和研究者应当关注和引入这类技术,以提升科研质量管控和知识传播的透明度。未来,结合更深层次的内容分析、大型语言模型和网络关系分析的多模态AI系统,将进一步增强对可疑出版行为的识别能力。长远来看,这不仅关乎单个期刊的评价,更影响着全球科研体系的公信力与可持续发展。研究人员也呼吁推动跨领域的合作,结合图书馆学、信息科学、数据科学与科研伦理的专业力量,共同构建透明、公正且高效的出版生态监测体系。
正如开放获取所倡导的科学普惠精神,保护学术诚信同样需要开放共享与集体智慧。综上所述,人工智能技术为评估和管理可疑开放获取期刊开辟了新的路径,助力科研共同体在信息爆炸和复杂多变的出版环境中站稳脚跟。这种技术驱动的辅助识别应被视为补充而非替代人类专家审查,二者的融合将是应对学术不端行为的最佳策略。全球学术界唯有携手利用先进技术,才能有效抵御可疑出版侵蚀,守护科学进步的纯净土壤。 。