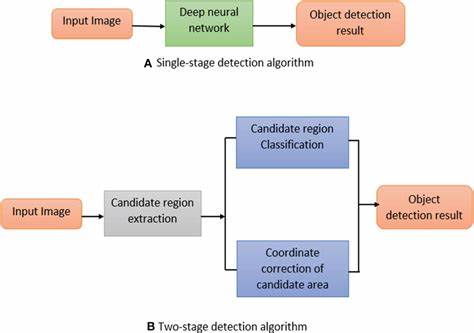
随着人工智能、大数据和高性能计算的快速发展,GPU已经成为加速计算的核心硬件。尤其是搭载Tensor Core的现代GPU,凭借其卓越的深度学习算力在计算领域占据主导地位。然而,要充分发挥Tensor Core的性能优势,除了硬件设计的改进,软件层面的优化同样不可忽视。Warp特化(Warp Specialization)作为近年来GPU编程和编译领域的研究热点,逐渐成为提升Tensor Core GPU并行计算效率的重要技术手段。Warp是NVIDIA GPU架构中用于执行并行线程的基本单位,通常包含32个线程协同工作完成特定计算任务。传统的线程调度策略往往将所有线程视为均质群体,但在实际应用中,不同线程执行的计算和数据访问模式存在显著差异。
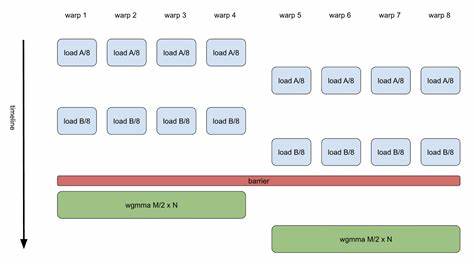
Warp特化技术通过识别和利用这种差异,将Warp中的线程进行精细化分工,从而提高资源利用率,减少执行等待和线程分歧,极大地提升计算性能。 Warp特化的核心思想是将复杂的计算工作拆分成不同类别的任务,赋予不同Warp以专门职责。比如在Tensor Core上执行矩阵乘法或张量计算时,不同的计算阶段对硬件资源的需求不同。通过Warp特化,可以让部分Warp专注于数据加载,部分Warp负责核心计算,另一些Warp负责结果写回和同步等工作。这样可以实现流水线式的软件管线,将GPU资源分配得更加合理和高效,最大化吞吐量。 现代GPU通常包含大量的Warp并行执行,然而由于分支分歧和内存访问延迟,实际的资源利用率往往低于理论值。
Warp特化通过减少分支路径的重叠和优化内存访问模式,有效缓解了这些性能瓶颈。举例来说,传统单一Warp执行多种任务时,需要不断切换上下文和调度状态,带来额外开销。而Warp特化则通过预先定义Warp角色,避免了这种频繁切换,提升了执行效率。此外,Warp特化在处理稀疏矩阵和不规则数据结构时表现尤为突出,因其可以根据数据结构特点灵活调度Warp,从而减少计算资源的浪费。 在软件实现层面,Warp特化结合自动化的编译技术尤为关键。研究人员开发了多种编译器优化手段,使得程序可以自动识别任务的不同阶段,将计算分配给相应的特化Warp。
与此同时,通过软件管线技术,实现任务之间的重叠执行,达到更高的工作效率。软件管线允许不同的Warp在不同时间同时处理计算中的不同步骤,形成连续的数据流和指令流。这种方式极大地提升了Tensor Core GPU在复杂计算中的吞吐能力,减少了硬件闲置和等待时间。 Warp特化技术的成功应用不仅在深度学习训练和推理等传统人工智能任务中带来性能提升,也对广泛的科学计算、图形渲染和数据分析等领域产生深远影响。通过合理设计Warp特化策略,可以适应多种领域的计算需求,实现计算资源的自主调度和动态分配,为多样化的应用场景提供定制化的性能优化方案。 此外,Warp特化还助力于解决GPU异构架构带来的挑战。
现代异构GPU通常结合了多个计算单位和内存层级,调度策略十分复杂。Warp特化通过软件和硬件协同,实现多个Warp之间的负载均衡和协作,从而提高异构系统的整体性能和能效。研究表明,通过Warp特化的自动映射算法,可以实现任务与硬件资源的最优匹配,显著降低延迟和功耗。 值得一提的是,Warp特化技术的发展离不开社区和产业界的共同推动。诸如NVIDIA、学术研究机构以及开源项目持续探索新方法,推动复杂应用在Tensor Core GPU上的高效运行。新颖的并行编程模型和运行时系统也不断涌现,为Warp特化的实现提供坚实的基础。
而面向未来,结合机器学习的自适应调度和预测机制或将成为Warp特化技术新的突破方向,通过动态感知和调节GPU的工作负载,实现更加智能和高效的并行计算。 综上所述,Warp特化在现代Tensor Core GPU中发挥着至关重要的作用。它不仅提升了并行计算性能,优化了资源使用,还促进了软件与硬件的紧密结合。随着相关技术的不断成熟,Warp特化必将成为GPU加速生态系统中不可或缺的核心组成部分。研究者和开发者应继续关注Warp特化相关的编译优化、软件管线实现和动态调度策略,以推动下一代高性能GPU计算迈向更高水平。 。