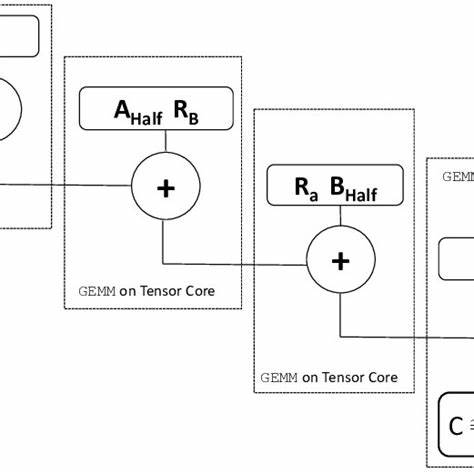
矩阵乘累加(GEMM)是高性能计算和深度学习中最核心的计算模式之一。随着硬件演进,NVIDIA推出了专用的张量核(Tensor Cores),通过MMA(Matrix Multiply-Accumulate)指令在硬件层面加速半精度和混合精度矩阵乘法。对于想要将性能最大化的工程师而言,仅仅知道有张量核并不能使你写出高效代码;理解MMA指令的线程级映射、寄存器片段格式、共享内存协调与内存对齐,才是把算力变成吞吐量的关键。本文围绕MMA张量核展开,从最小可运行的微核(microkernel)切入,逐步扩展到完整的GEMM实现,并讨论常见的优化方向与工程权衡。通过逐步推导与实战建议,你能对自定义张量核实现的设计有清晰的认知,并判定在何种场景下值得替换cuBLAS等成熟库。 先从基本概念说起。
GEMM可以抽象为C = A * B + C,其中A、B、C分别为矩阵。张量核的MMA指令以warp为单位运作,即32个线程协作完成一个小规模矩阵乘累加。常见的PTX指令形式类似于mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32。解读这条指令可以直接帮助我们理解寄存器中数据如何被组织与消费。m16n8k16代表一次MMA操作负责将一个16×16的A与16×8的B相乘产生16×8的结果;row与col分别描述A的行主序与B的列主序;后缀f32/f16表明输出为单精度累加,输入为半精度浮点数。理解这些语义后,我们可以设计一个每个warp负责计算一个16×8输出tile的微核。
实现微核的第一步是弄清楚每个线程需要在寄存器中持有哪些数据片段(fragment)。PTX文档给出了详细映射,指定每个lane(即warp内的线程编号)要加载A、B矩阵哪些元素。通常A矩阵的片段会以8个16-bit元素(即每线程保持8个半精度)组织成用于寄存器读取的格式,B片段可能只有4个元素,C的片段用于累加并最终写回全局内存。按照文档计算row/col映射后,就可以在每个线程内以散列加载方式从全局内存或共享存储上填充这些寄存器片段。但需要注意,直接从全局内存按线程散点读取会造成非连续访问,严重影响带宽利用率与缓存效率,因此需要更好的载入策略。 为了解决片段加载的效率问题,PTX提供了ldmatrix指令,它可以将共享内存中的连续块高效地载入为MMA所期望的寄存器片段。
对于半精度输入,通常以8×8的小块为粒度进行加载,并支持一次加载多个块,例如ldmatrix.sync.aligned.m8n8.x4.shared.b16可在warp内并行将4个8×8块载入寄存器。使用ldmatrix的前提是将输入矩阵切分并按照特定对齐(例如alignas(16))写入共享内存,从而保证线程组可以协同地进行矢量化加载。对B矩阵则通常使用转置版本的ldmatrix(例如...trans.b16),以便满足MMA指令对B的列主序要求。合适的共享内存布局不仅能减少地址计算开销,还能避免SMEM bank冲突,从而提升吞吐量。 有了片段加载机制,我们可以构造一个基本的microkernel:每个block只包含一个warp,warp内线程先协作将对应的A和B小块搬到共享内存,再通过ldmatrix将这些块读入寄存器,随后调用mma.sync指令完成一次16×8的矩阵乘累加。累加结果保存在每线程的C片段寄存器,完成全部K分块的累加后再写回全局内存。
该微核在逻辑上是完整的,但只适用于M=16、N=8、K=16的最小尺寸;要扩展到任意大小矩阵,需要在block/grid层面做平铺(tiling)。 扩展到完整GEMM时,将输出矩阵分割为多个16×8的tile,每个tile由独立的block计算。Grid尺寸的x方向负责覆盖N维(以8为步长),y方向负责覆盖M维(以16为步长)。在计算含有更大K维的GEMM时,将K分段为多个16的步长,逐段加载A和B的对应片段并进行累加。这里要注意地址偏移的细节:在每次K段迭代结束后,A指针需右移16列而B需向下移动16行(或按连续存储布局移动相应偏移),这样分段累加可正确地构成C的每个元素的最终值。因为累加发生在寄存器中,只有在完成所有K段后才进行一次写回,从而减少内存写入频次并利用寄存器带宽完成更多的计算工作。
尽管上述实现在功能上是正确的,但实际性能往往远低于成熟实现如cuBLAS。这通常归因于数据移动的低效。硬件计算单元的能力远胜于内存子系统,因此关键优化方向是减少内存访问次数、提高访问连续性与复用率,并使用异步或双缓冲机制隐藏数据传输延迟。实现思路包括在共享内存中构建更大的A、B片段缓存、使用双缓冲或循环展开在计算与数据搬入之间重叠、精细管理SMEM对齐以避免bank冲突,以及尽量将内存访问合并为向量化加载以提高带宽利用率。 针对warp级MMA,额外的优化要点还包括充分利用寄存器文件,避免寄存器溢出导致的溢写回内存,以及通过指令级并行(ILP)安排多个ldmatrix和mma指令的并行发射。还可以考虑在块内采用多个warp合作处理更大的tile,从而实现更高层次的数据复用,但这会增加线程间协调成本与同步开销。
另一条常见路径是使用更高层次的许多商用框架中采用的分层优化策略:外层以高效的L3/L2缓存友好布局组织,内层以共享内存和张量核为核心实现高频复用。 关于工具链与兼容性,MMA与ldmatrix等PTX指令与CUDA版本和GPU架构密切相关。不同架构在张量核能力、支持的指令集与存储指令(如stmatrix)上存在差异。较新的架构(例如Hopper)引入了stmatrix等指令,允许更高效地将寄存器内的矩阵片段回写到共享或全局内存,从而进一步提高吞吐。当你编写自定义内联PTX时,需要关注目标架构的PTX语义、对齐要求(例如ldmatrix常要求16字节对齐)和寄存器约束,否则容易在运行时出现错误或性能退化。使用__cvta_generic_to_shared等设备函数可以获得共享内存地址的正确转换,而在内联汇编约束中要精确声明寄存器输入输出类型以避免编译器的错误寄存器分配。
工程上是否应当放弃cuBLAS而使用自研MMA实现,取决于应用场景。对于常见的、尺寸多样、对数值稳定性与性能有苛刻要求的生产任务,cuBLAS经过高度调优和持续维护,通常是首选。自定义实现适合于对特定矩阵尺寸、特殊数据布局或极致延迟/吞吐有硬性要求的场合,或者当你需要实现某些cuBLAS不支持的混合精度矩阵操作与自定义融合算子时。自研实现的代价主要包括维护、跨架构适配、测试与数值验证等,因此在决定投入前应进行小范围性能原型验证。 数值精度和累加顺序也是必须考虑的问题。典型的MMA配置使用半精度输入与单精度累加,这在深度学习推理和训练中常能在性能和精度之间取得良好折中。
然而某些数值敏感场景需要更高精度或更稳定的累加顺序,这时需要评估混合精度带来的误差传播并可能引入分块或Kahan类的补偿算法来控制误差,但这会付出性能代价。 整合工程实践建议包括优先用性能分析工具(如NVIDIA Nsight Compute、nvprof等)度量内存带宽占用、SM利用率、张量核利用率与指令瓶颈。用轻量级微基准测试不同K尺寸下的吞吐变化,找到哪些K值段导致性能下降,再以调度或算法改造减轻这些低效区间。在内存布局上优先保证连续访问、对齐与按向量化宽度加载。对共享内存进行排布时,需要意识到bank冲突,并尽量让线程组的访问模式避免跨bank竞争。最后,逐步增加复杂性,从可验证的微核到完整GEMM实现,能更快定位性能问题。
随着硬件演进,张量核的指令集合与内存指令也在不断扩展,为自定义高性能实现提供了更强的工具。掌握MMA与ldmatrix的基本语义、寄存器片段映射、warp级协作模式和共享内存对齐细节,是能够高效利用张量核的敲门砖。通过从最小可运行的16×8 tile出发,逐步扩展到覆盖任意可分配尺寸并逐段处理K维,你不仅能实现正确的GEMM,还能在此基础上探索异步拷贝、双缓冲、寄存器分配优化等高级技巧,逐步逼近库级性能。 总结来看,张量核为矩阵乘法提供了强大的硬件支持,但要把理论性能变成实际吞吐量,需要对指令语义、线程映射、共享内存布局与内存访问模式有深入理解。把握微核设计、利用ldmatrix进行高效载入、通过分块并累加K段来扩展到完整GEMM,再用分析工具定位性能瓶颈,是工程实践的有效路径。希望你在动手实现和调优过程中,能把握好精度与性能的权衡,谨慎决定何时采用现成库或自定义实现,并通过迭代优化把张量核的潜能转化为可观的加速效果。
祝在CUDA与张量核的深度优化之路上取得突破并收获高性能的结果。 。