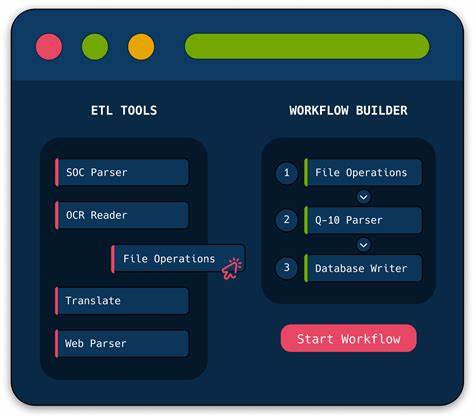
在当今快速发展的数字时代,企业和组织正面临着海量非结构化数据的挑战。这些数据来自于各种渠道,例如电子邮件、PDF文档、社交媒体等,如何高效地将这些非结构化数据转化为可用的信息,成为了企业决策的关键。最近,一款名为“Unstract”的无代码平台应运而生,它利用大型语言模型(LLM)为企业提供了一个便捷的解决方案,能够有效地提取、结构化并处理非结构化文档数据。 Unstract的核心是其无代码的特点,让用户无需编写任何代码即可创建API和ETL(提取、转换和加载)管道。传统上,构建这样的系统通常需要具备编程技能和庞大的技术团队,而Unstract则打破了这一壁垒,使得各类用户 — 从数据科学家到业务用户 — 都能够轻松上手。通过直观的界面和简化的操作流程,用户可以在“Prompt Studio”中快速开发出高效的文档数据提取方案。
在Prompt Studio中,用户可以上传所需处理的文档,并进行实时的提示工程(prompt engineering)。这个过程不仅简单,而且鼓励用户通过实验来优化他们的提取方案。用户可以轻松查看和对比不同LLM的输出效果,并根据需要调整提取的字段和格式。此外,Prompt Studio还提供了详细的成本分析功能,让用户能够更科学地评估数据提取的费用。 在整合了文档处理的简单性和API部署的灵活性之后,Unstract的工作流程可以分为三个简单的步骤。第一步是将 documents 提交到Prompt Studio,并设计提取所需的字段;第二步是将项目配置为API部署,或者设置输入源和输出目标,为ETL管道准备;最后,用户可以将工作流部署为非结构化数据API或ETL管道,实现业务流程的自动化。
Unstract的一个显著优势在于其广泛的生态系统支持。该平台与多个大型语言模型供应商进行了集成,包括OpenAI、Google VertexAI、Azure OpenAI等,用户可以根据自己的需求灵活选择。此外,在向量数据库领域,Unstract也与多个领先的数据库供应商合作,确保用户在数据存储与查询上的灵活性。 例如,在处理信用卡账单等财务文档时,用户可以经过简单的配置,从上传文档到生成结构化数据API,整个过程只需短短几分钟。这样一来,企业不仅能提升工作效率,还能降低人工成本和错误风险。 对于想要深入了解Unstract的用户,该平台提供了丰富的文档和“快速上手指南”。
用户可以通过连贯的教程和示例,迅速掌握如何与不同的系统进行连接,比如向量数据库、嵌入模型和文本提取器。这样的设计理念,充分体现了Unstract团队对用户体验的重视。 为了进一步增强社区交流与合作,Unstract还开设了Slack频道,让用户和开发者能够实时分享使用经验和技巧。这种开放的态度不仅促进了技术的传播,也带动了更多的开发者参与到这个生态系统中来。 当然,Unstract并不止步于此。随着技术的发展,该平台还计划不断推出新功能和支持的供应商,以满足不断变化的市场需求。
例如,有关适配器和认证信息的安全性也得到了极大的重视,用户必须妥善保管加密密钥,以确保其数据的安全性和可访问性。 在分析和利用数据方面,Unstract进行了深思熟虑的设计。为了帮助用户更好地理解使用情况,平台集成了Posthog进行使用分析,旨在收集最少的必要指标,确保用户在使用过程中得到最佳体验。同时,用户有选择权,可以在个人设置中禁用该分析功能。 在未来,Unstract希望能够继续扩展其功能和服务,使其成为处理非结构化数据的首选平台。随着机器学习和人工智能技术的快速发展,Unstract的无代码平台将为企业的数字化转型和智能自动化提供更多可能性。
总的来说,Unstract提供了一种全新的思维方式,以应对现代企业面临的非结构化数据挑战。通过无代码的平台,用户无需依赖技术团队,即可快速地实现数据提取和处理的需求。这不仅将极大地提高工作效率,还能帮助企业从繁杂的数据中提取出有价值的信息,推动业务的进一步发展。 随着对数据分析和整合需求的持续增长,Unstract无疑将成为未来企业数据处理的重要工具,帮助各类企业在数据驱动的时代把握住机遇,迎接挑战。无论是中小企业还是大型组织,Unstract都提供了一种高效、灵活、可靠的数据处理方案,助力它们在激烈的市场竞争中立于不败之地。









