随着人工智能和大数据技术的迅速发展,矢量搜索在图像识别、推荐系统以及自然语言处理等领域的应用日益广泛。CatBench作为一款基于Postgres与PgVector的示范应用,借助25,000张猫咪照片数据集,生动展示了矢量相似度搜索如何无缝集成至传统关系型数据库的应用架构中,为业内开发者和研究人员提供了宝贵的实践参考。近期,CatBench更新至0.3版本,最受关注的改进便是新增的Postgres实例级别的吞吐量与平均查询执行延迟监控功能。此举不仅提升了应用的可观测性,也为开发者提供了更细致的性能分析工具,有助于优化查询效率,改善用户体验。CatBench的核心理念是将传统的SQL查询与矢量相似搜索结果进行整合,打造一个真实且具交互性的推荐系统原型。在演示界面中,用户可以浏览猫咪商品推荐,点击任何一张照片,即可基于视觉相似度得出与其他相似猫咪用户购买记录相关的产品建议。
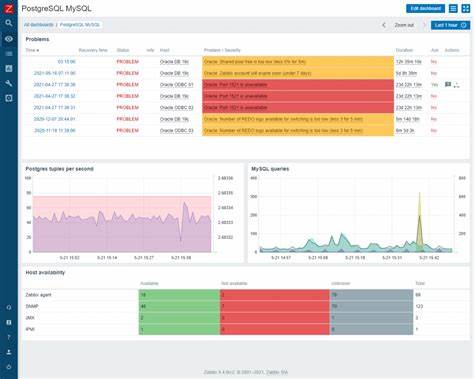
这种协同模式切实体现了矢量搜索与关系型数据的深度融合。随着查询操作的复杂度增加,实时监控数据库内部运行状况变得尤为重要。新版CatBench引入了在应用中直接访问Postgres实例查询吞吐量及延迟的图表展示,用户可通过应用主页上的“监控”按钮即时查看。监控模块不仅显示实例范围内的SQL查询执行速度,还以可视化图形直观呈现查询频率和响应时间变化趋势,从而助力发现瓶颈及潜在优化空间。开发者在压力测试中逐步增加并发相似搜索查询数量,能够准确观察系统吞吐能力和延迟表现,进而进行针对性调优。值得指出的是,CatBench对每条后端查询均执行两次,第一次使用EXPLAIN (ANALYZE, BUFFERS)命令获取物理块I/O次数及执行计划指标,第二次实际执行查询以展现数据结果。
这种策略确保开发者既能洞察底层查询成本,也能看到最终查询成果,有效提升性能调试的深度和精准度。此外,监控界面还提供了查询排名表,用户可一目了然地获知最耗资源或者执行最慢的SQL语句,以便优先进行性能优化。虽然当前缓冲区活动指标因执行大量PL/PgSQL循环存在数据更新延迟问题尚有提升空间,但这一功能已展示了动态监控复杂矢量搜索负载的潜力,为后续完善奠定基础。未来,CatBench计划在数据规模和功能层面进行大幅扩展。通过创建359倍新增旋转变体,实现从25,000张照片向九百万数据量的爆炸式增长,这不仅拓展了测试范围,也为研究矢量搜索召回率及精度提供坚实数据基础。同时,启动针对“猫咪欺诈检测”反向查询的召回质量监测,为不同向量索引类型及配置方案比较提供科学依据。
更为远期目标包括将CatBench重构以支持其他数据库系统,不仅仅为了横向性能对比,更旨在通过多数据库环境掌握矢量搜索技术的跨平台适配性和优化实践,从中汲取更广泛的经验与洞见。CatBench的开源性质也为广大开发者社区提供了极佳的学习和实验平台,借助完整的查询日志、执行计划与性能指标,即使不具备顶尖数据库调优经验的用户,也能深入理解关系型数据库如何融入现代AI驱动的矢量搜索功能。在持续完善自动化参数调整工具之前,用户需手动自定义数据库设置及向量索引参数,以体验并对比秩序召回和效率表现差异。此实践过程不仅培养了调优思维,也促进了对底层技术机制的认知。整体来看,CatBench代表了一种全新的数据库应用探索路径,既体现了Postgres作为多功能关系型数据库的强大适应力,也展现了PgVector扩展对高效相似度搜索支持的成熟度。通过结合传统SQL查询和矢量向量引擎,开发者能够构建更智能且响应迅速的应用,实现从数据存储到智能推荐的无缝连接。
未来随着硬件性能提升与算法创新,类似CatBench这样的工具必将助力更广泛领域的深化落地,推动数据库与人工智能技术实现更为紧密的融合。对于关注数据库性能优化、矢量搜索以及应用监控的工程师与研究者来说,持续关注CatBench及其更新动态,参与社区讨论,将有助于掌握最新技术趋势并提升实战技能。总结来看,CatBench不仅通过丰富数据与交互设计,生动阐释了Postgres与PgVector协同工作的强大潜力,而且通过新增加的吞吐量与延迟监控功能,显著提升了性能可视化水平,注定成为未来关系型数据库矢量搜索技术实验与演示的重要平台。随着功能完善与数据规模扩展,其无疑将在数据库领域的教学、实验和生产环境中发挥更大价值。