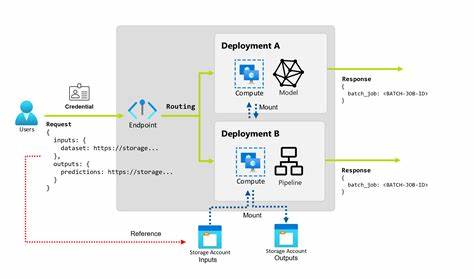
随着人工智能技术的迅速发展,尤其是大语言模型在自然语言处理领域的广泛应用,如何有效管理和调度大规模并发请求,成为了AI平台设计中的关键难题。开源批处理端点(Open Source Batch Endpoint)应运而生,作为一个高性能的批量处理API,它支持单GPU和多GPU(最多达24块GPU)部署,极大提升了大语言模型的推理效率和系统吞吐量。本文将深入剖析这一工具的技术架构、优势特点以及最佳部署实践,帮助AI开发者和企业用户轻松驾驭大规模模型服务。首先,从功能层面来看,开源批处理端点提供了智能队列管理和先进的并行处理功能。智能队列管理基于Redis实现,能够高效分发和调度批次任务,保证各个worker节点合理负载,避免资源闲置或过载情况发生。并行处理方面,端点支持同时运行多个worker,最大化利用GPU资源,从而实现任务的水平扩展。
用户可以根据硬件配置自由调整worker数量,充分发挥8-GPU甚至24-GPU集群的算力优势。除了负载均衡外,系统设计还注重可靠性和容错能力。即使个别worker节点发生故障,其他节点仍能继续处理剩余批次,保证服务稳定不中断。同时,端点提供持久化存储方案,确保批处理任务数据安全可靠,可追溯和重现。可视化的实时分析仪表盘也是其一大亮点。用户能够实时监控系统吞吐量、上传量及各类统计数据,直观掌握系统运行状况,及时发现瓶颈和异常,便于后续优化调整。
部署上,端点提供丰富的Docker Compose配置,支持单节点和多GPU集群灵活切换。标准版适合单GPU应用场景,用户只需简单运行docker compose命令即可启动服务并自动扩展worker。而对于生产级高性能需求,24-GPU配置结合Nginx负载均衡,支持多节点机器集群,极大提升并发处理能力。性能优化方面,建议合理配置最大worker数量与并发批次参数,结合硬件性能找到最佳平衡点。例如在使用NVIDIA H100 GPU时,推荐worker数值可达128以提升资源利用率。同时,网络连接数配置也需高于最大worker数量,避免因系统限制导致连接瓶颈。
此外,模型加载策略影响初始化速度。多GPU部署时,建议一次性上传模型文件,缩短启动时间。需要注意的是,系统当前尚不包含自动存储管理机制,用户需手动清理旧批次输入输出文件,避免磁盘空间紧张。安全和测试工单方面,开源端点提供丰富的接口支持快速验证模型推理正确性及API健康状态。用户可直接调用vLLM兼容的推理端点,进行多样化测试,保障部署质量。虽然官方暂未提供GPU专项的自动化测试脚本,但推荐结合预设的Python测试示例,辅助检测部署状况。
开源批处理端点还支持命令行工具,用于管理批处理任务,包括查询特定批次状态和清理数据文件。对于持续集成持续部署(CI/CD),有专门的更新命令,便于无停机部署API微服务,保障业务不中断。作为一款Apache-2.0开源项目,端点鼓励社区贡献和定制扩展。无论是缺陷修复,还是功能优化,开发者都可通过GitHub提交issue或pull request积极参与,共同推动项目发展。其代码采用Python为主,兼具Shell脚本和Dockerfile,确保跨平台和容器化部署的灵活性。总之,开源批处理端点通过智能的队列机制、灵活的多GPU支持、实时监控与稳健的架构设计,为大语言模型提供了一套强大且易用的批量推理解决方案。
借助该工具,AI开发团队能够显著提升推理效率,优化资源利用,满足不断增长的业务吞吐需求。未来,随着更多社区贡献和技术演进,预计该项目将在AI基础设施领域发挥越来越重要的作用。掌握并灵活应用这一开源工具,将为企业级AI产品研发打下坚实基础,引领智能时代的技术创新浪潮。 。