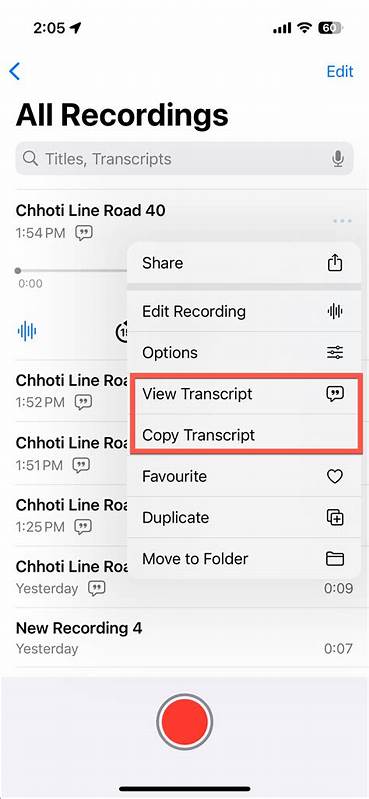
在数字时代,录音笔记逐渐取代传统的纸笔记录,成为许多人记录灵感与想法的首选工具。苹果的语音备忘录应用凭借其便捷的录音功能和自动转录能力,深受众多用户喜爱。尤其对于经常在路上、散步或开会时捕捉瞬间灵感的人来说,这款应用优势明显。然而,许多用户会发现一个尴尬的现实:虽然语音备忘录能自动生成转录文本,但苹果官方并未提供直接获取这些文字内容的通用方式,导致用户必须通过极为笨拙的复制粘贴来使用这些转录内容。为何苹果会设计这样一种封闭体系?转录文本究竟隐藏在何处?本文将深入探讨苹果如何存储语音备忘录的转录数据,并分享一套方法帮助用户从音频文件中完整提取文字内容,实现录音文本的自由应用与管理。苹果语音备忘录是基于.m4a音频格式,其实.m4a文件并非单纯的音频数据容器,而是一种复杂的多媒体封装格式,支持嵌入视频、图片、元数据以及文本信息。
这种封装结构源自ISO/IEC 14496标准,俗称“容器格式”,由一层层称为“原子”或“盒子”的数据块组成。苹果在标准基础上自定义了一种名为“tsrp”的特殊原子,用于存储语音录音对应的转录内容。这个“tsrp”原子类似于一个秘密的信封,隐藏在音频文件深处,表面上看不见也无法直接访问。通过现代逆向工程手段,聪明的开发者发现这个tsrp原子里面本质上存储的是一段JSON格式的字符串,里面详细记录了语音转录文本的每个字词及对应的时间戳。正因如此,虽然在苹果官方应用界面无法导出转录文本,但只要掌握正确的方法,就能从音频文件直接解析并恢复文字内容。解析该原子需要一定的技术背景。
使用命令行工具如strings可以在.m4a文件中搜索包含“tsrp”标识的文本块。结合rg和sed筛选出以“tsrp”开头的JSON串,再以jq等JSON解析工具提取其中的转录文字数组及对应的时间区间,便可完整重建音频对应的文字稿。值得注意的是,该JSON结构中“runs”字段包含了按顺序排列的词汇,每个词后跟着一个数字索引;“attributeTable”字段包含对应词汇的时间范围,单位为秒。精确匹配这些数据,可实现逐字逐句的时间同步转录文本。这一发现不仅拉开了普通用户手动复制的局限,更为开发者打造智能工具打下了坚实基础。苹果当前并未公开“tsrp”原子的官方文档,一切信息均来自逆向分析和社区探索。
但可以合理推测,苹果选择将转录文本直接嵌入.m4a文件,一方面方便同步和携带,避免依赖外部数据库,保证音频与文本信息的一致性与完整性;另一方面也可能是保护生态系统的一部分,限制文本的开放提取以维护用户隐私和版权。从标准角度看,MPEG-4标准允许容器中包含文本流,供字幕或注释使用,但苹果起用了自定义的tsrp atom,将数据以JSON形式保存,既保持了极好的扩展性,也满足了文本的结构化需求。换言之,苹果创造了一种较为灵活且内部高效的解决方案,将音频与对应的时间同步文字记录集成到一起,同时方便自身应用的快速读取与展示。技术爱好者和专业用户可利用开源脚本或命令行工具组合实现自动批量提取。例如,利用mp4extract工具根据路径定位“moov/trak/udta/tsrp”原子,并通过--payload-only选项获取纯文本数据。接着用jq对内容做进一步解析和筛选,去除非文本数据,拼接文字内容,就能快速获得完整转录文本。
这样一套流程彻底解放了语音备忘录转录字数限制及导出不便的难题,大幅提升语音数据的二次利用价值。通过将音频与文本统一存储,用户再也不用烦恼找不到文字内容,或者因转录文本和录音分离造成的文件管理复杂。对专业工作者、创作者和日常记录者来说,这无疑是提升效率和创新能力的利器。例如,记者采访录音可以快速转写成文章雏形,研究员会议记录能自动整理内容要点,普通用户更能随时检索过去的点滴想法,不再被海量语音资料淹没。苹果语音备忘录隐藏转录文本这一设计其实体现了数字媒体封装技术的极致应用。它既保证了数据的完整传输,也为音视频文件赋予更多语义层面内容,使音频不止于声音,更成为富信息载体。
掌握了相关知识和工具,无疑在新时代内容管理上占有先机。回顾整个过程,我们看到了标准与定制、封闭与开放、技术细节与用户体验之间的博弈与平衡。未来,随着技术发展和用户需求变化,也许苹果或第三方将提供更友好、更自动化的导出和编辑工具,进一步打破现有局限。与此同时,用户自己也能利用逆向分析和脚本工具,打造专属的语音文本工作流,实现真正的数据掌控力。无论你是技术发烧友,还是日常记录者,理解和解锁苹果语音备忘录内部的转录秘密,都是迈向高效内容管理的重要一步。将这套方法融入习惯,必将帮助你在信息爆炸时代游刃有余,事半功倍。
。