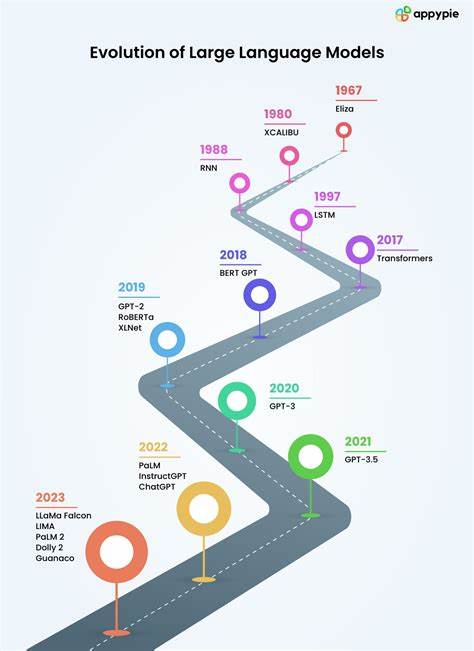
语言模型作为人工智能领域的一项核心技术,经历了从简陋到复杂的发展过程,推动了自然语言处理(NLP)的众多突破。它不仅让机器能够理解和生成自然语言,还逐步实现了某些层面上具备类人能力。本文将结合历史发展与技术细节,详细梳理语言模型的演化历程,揭示其背后不断创新的技术引擎和面临的挑战。 语言模型的起点可以追溯到上世纪中叶。1955年,约翰·麦卡锡在达特茅斯人工智能研讨会提案中期待通过科学家们的集体努力,使机器能够使用语言、形成抽象和概念,解决传统上只能由人类完成的问题,并实现自我改进。虽然当时的设想极富远见,但要达到真正流畅自然的语言交流,机器仍然面临巨大困难。
1949年,艾伦·图灵提出了著名的图灵测试,作为衡量机器语言能力的标准,使得人工智能研究有了明确的目标。数十年后,随着计算能力和算法的进步,机器终于在控制环境下通过了严格的图灵测试。例如,GPT-4.5在测试中以73%的概率被评审误认为是人类,对比图灵构想时所设想的时间,实则经历了139个夏天的打磨与发展。 最初的语言模型构建方式集中了马尔可夫链的思想。马尔可夫链基于随机过程理论,模拟系统如何从一个状态转移到另一个状态,其核心在于当前状态的依赖关系,比如天气变化可以从晴天概率转为阴天或雨天。克劳德·香农作为达特茅斯会议的早期参与者之一,便采用字符级马尔可夫链完成了文本文字的近似生成。
然而,字符级别的马尔可夫链产生的文字通常是毫无意义的乱码,因为仅依赖单个字母预测下一字符的上下文信息极其有限。通过提升模型的阶数,即增大上下文长度,比如考虑3至6个字符,虽然理论上能够提高连贯性,但代价是模型复杂度呈指数增长,内存需求激增。同时,高阶马尔可夫链因过拟合训练语料,往往倾向于直接复述训练文本,限制了模型生成创新内容的能力。 词级马尔可夫模型同样存在局限,主要体现在不能生成训练语料库中未出现的新词汇,限制了模型的语言创造力。对此,研究者引入了介于字符和单词之间的“词元”概念,词元通常代表类似于音节的语言片段,既避免了字符级模型自由度过高生成乱码,也解决了词级模型过于死板的生成限制。 词元的实用实现中,字节对编码(Byte Pair Encoding,简称BPE)脱颖而出。
BPE算法核心思路是先将文本拆解成单字符序列,统计频繁出现的相邻字符对,将出现频率最高的字符对合并为新的词元,不断迭代,最终形成包含常用词缀和词根的词元表。此过程不但优化了文本表示,还起到了类似压缩的作用。 通过BPE编码,语言模型的输入不再局限于单一字符或完整单词,而是灵活地使用词缀级别的中间单位,显著增强了模型对语言结构的捕捉能力。例如,常见的词缀“ing”或高频词“for”、“and”均能成为独立词元,使得生成的内容更贴近人类语言表达,且允许对未知新词进行合理组合和生成。 现代大型语言模型(Large Language Models,简称LLMs)诸如GPT系列进一步迈出了关键一步。相比传统的固定权重马尔可夫模型,GPT引入了自注意力机制(Self-Attention),能够动态地赋予上下文中的不同词元不同权重,捕获长距离依赖关系,并基于上下文语义生成更连贯、逻辑性更强的文本。
自注意力机制使得模型可以考虑整个输入序列中各个词元相互之间的影响,而非简单地采用均等权重或固定步长。GPT利用这一机制在预训练阶段学习大规模文本数据中的语言规律和知识,然后通过特定任务的微调,展现出强大的生成、理解和推理能力。 以GPT-2为例,其所搭建的多头注意力结构能够从多个视角并行处理上下文信息,这种设计极大提升了模型对复杂语言现象的把控能力。许多可视化研究展示了不同注意力头对句法结构、语义关系及指代消解等语言特性的敏感度,体现了深层神经网络对自然语言的深度理解。 通过实时亲自训练一个小型GPT模型,可以直观感受到其相较于马尔可夫链模型在生成效果上的质的飞跃,即使是在相同的数据和基础词元分割方法下,GPT生成的文本远比马尔可夫链的线性概率模型更自然且富有逻辑连贯性。 语言模型在发展过程中不断攻克各种技术难题,从语言多样性和上下文理解,到生成连贯和创新文本,经历了长时间的技术积累和改良。
即使是现今备受关注的GPT系列,也只是站在巨人的肩膀上,融合了概率统计、神经网络与优化算法的综合成果。 未来,伴随着计算资源的提升和算法的持续创新,语言模型有望在交互智能、语言理解、知识推理等多方面达到更高的水平。这不仅会推动人工智能在教育、医疗、法律等多个领域的实际应用,也将在机器与人类沟通的边界上持续刷新想象力。 纵观语言模型历史,从最初简单的马尔可夫链,到引入字节对编码,再到自注意力驱动的预训练变换器,每一步进化都承载着科研人员对语言本质的更加深入理解与技术创新。它揭示了人工智能追求自然语言表达的漫长征程,以及人类赋予机器语言智慧的美好愿景。









