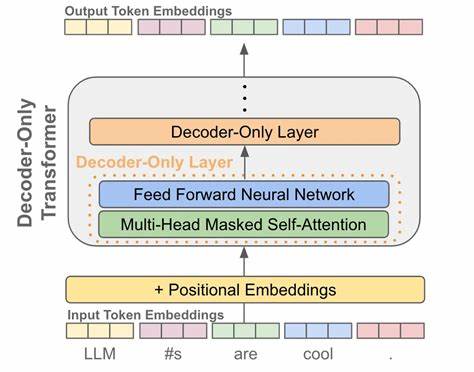
近年来,大语言模型(LLM)的迅猛发展和广泛部署,极大地推动了人工智能在自然语言处理领域的应用。从自动写作辅助、智能客服到机器翻译和内容生成,LLM的影响力正以前所未有的速度扩展。然而,随之而来的海量生成文本数据不仅加重了存储和传输的负担,也对数据管理系统提出了更高的压缩效率要求。传统压缩算法如Gzip虽然历史悠久且应用广泛,但面对多样且复杂的LLM生成文本表现出明显的局限性。最近研究显示,基于LLM自身的下一词预测机制,能够针对其输出内容实行高效的无损压缩,开启了新一代压缩技术的新纪元。 大语言模型生成的文本与传统数据在结构和内容特征上存在显著差异。
传统机器生成数据往往是高度结构化的数值或者标签信息,便于利用已有的统计模型或字典编码方法进行无损压缩。相比之下,LLM生成的文本复杂多变,包含丰富的自然语言内容,语义层次繁复且上下文关联强烈。这种特性导致传统压缩工具难以捕捉文本中的内在规律,进而限制了压缩比的提升。研究人员通过深入分析LLM的训练机理发现,LLM本质上就是通过预测给定上下文的下一个词而学习语言模型的。因此,利用LLM自身的预测能力,可以准确预估文本的可能出现,从而实现针对性极强的无损压缩。 在实际应用中,研究团队利用14个代表性的大语言模型及8个覆盖不同领域的LLM生成文本数据集进行了系统测试。
结果表明,利用LLM作为预测器的压缩算法,能够实现超过20倍的数据压缩率,远远超越传统Gzip等通用压缩工具约3倍的压缩效率。这一显著提升不仅彰显了基于深度学习模型的压缩方案的优势,也表明该技术具备广泛的适应性和稳定性,适合多种文本类型与规模。 从技术细节来看,基于下一词预测的压缩方法主要通过模型对输入文本进行概率估计,预测可能出现的词汇分布。随后利用熵编码等经典信息论工具对文本的每个词按照其出现概率进行编码,使高概率词汇用更短的编码表示,低概率词汇用相对较长的编码,从而最大限度减少整体数据长度。值得一提的是,这一过程完全保留原始文本的所有信息,确保无损恢复,满足严格的数据完整性要求。 由于很多应用场景中,LLM已经被部署为服务端生成内容,利用相同模型进行压缩还可实现无缝集成,减少运算开销,提升系统整体效率。
更重要的是,这种压缩方式具有良好的扩展性,能够随着模型规模和性能的提升,持续优化压缩率表现,未来潜力巨大。 在数据安全和隐私保护方面,基于模型的压缩需要处理敏感文本内容,因此设计合理的访问控制和加密机制非常关键。同时,如何减轻模型计算负担,提升实时压缩速度,也是推进该技术应用的重点研究方向。业内专家认为,结合硬件加速器和分布式计算,将有望突破现有瓶颈,让无损压缩技术更快走向商业化落地。 总体来看,基于大语言模型自身的下一词预测实现的无损压缩技术,不仅为庞大的LLM生成文本数据管理带来革命性改进,也将极大推动人工智能产业的健康发展。面对日益增长的数据存储和传输挑战,这种结合深度学习与信息论的新兴方法正成为未来文本压缩领域的重要趋势。
随着研究不断深入和工程实践的推进,可以预见LLM生成文本的无损压缩技术将在更多应用场景落地,推动数字内容生态进入高效、智能的新阶段。









