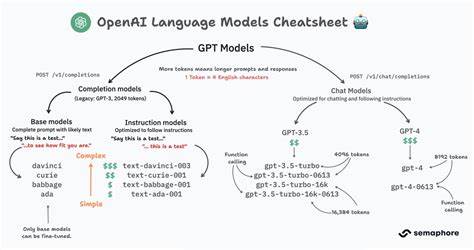
随着人工智能技术的迅猛发展,OpenAI作为行业的领军者,其推出的各种模型备受关注。然而,众多模型背后的命名及架构常常让公众和从业者感到困惑。理解OpenAI模型的层级关系、训练方法及未来走向,有助于把握AI领域的发展脉络和前景。本文将从基础模型谈起,深入探讨OpenAI模型的演化路径,梳理其推理训练和模型蒸馏机制,最后展望即将发布的GPT-5模型,助力读者从全局视角认识OpenAI的AI布局。 OpenAI模型体系的核心在于一个以基础模型为起点的复杂依赖图,这张图代表了不同版本模型之间的改良和变种关系。基础模型通常在预训练阶段投入大量算力,完成对海量文本的语言模式学习。
基础模型基于算力投入的多少,其规模和能力呈现出显著差异。近期OpenAI公布的基础模型包括GPT-4o、GPT-4.1和GPT-4.5,每一代均在规模和训练深度上有明显提升。 随着技术的进步,OpenAI在2023至2024年之间,开始引入推理训练,这是在基础模型预训练之后,用强化学习和高质量数据微调模型的过程。推理训练不仅让模型在传统的语言理解上表现出色,更提升了其在数学、编程和科学推理等领域的能力。这类模型通常以“o1-preview”或“o1”等命名出现,是对基础模型的重要性能增强。 一方面,强化学习通过自动评分的链式思考过程引导模型完成难题,成功解题的策略会被强化,错误则被抑制。
这要求问题具备自动判定正确与否的标准,方便大规模训练。另一方面,利用高质量解题实例生成合成数据集,也成为提升模型推理能力的有效手段。这些融合了复杂推理的后训练提升了AI对复杂任务的适应性。 除了推理训练,OpenAI还采用了一项名为“蒸馏”的技术,即通过训练一个较小的模型来模拟大模型的输出。这种做法能够在不显著牺牲性能的情况下,极大降低计算和推理成本。为此,OpenAI开发了被称为“迷你mini”系列的模型,如GPT-4o-mini、o1-mini等,它们在API中提供了更经济的选择。
通过蒸馏技术,用户可以获得接近大模型的性能,同时享受更低的成本,这在实际应用中意义重大。 在众多OpenAI模型中,编号和命名背后的逻辑并非公开透明,而是基于内部的一套复杂体系。主流猜测认为,各个模型本质上是不同基础模型加上不同阶段推理训练和蒸馏结果的组合。通过结合各模型的知识截止时间和API定价,研究团队能够推断模型大小及其相互关系,但具体细节仍为商业机密。 一个令人关注的事件是关于o3模型的两次发布。2024年12月,OpenAI公布过一款o3模型,展示了该模型在各种基准测试中的优异成绩,尤其是在ARC-AGI测试中表现突出。
然而因推理阶段计算资源消耗极其巨大,该版本未能正式对外开放。数月后,2025年4月,OpenAI发布了另一版本的o3,性能较前一版有所差距。业内普遍认为,首版o3基于更大或更先进的基础模型,使用了大量推理算力,因成本过高不适合商业化,而后期版本则是对更便宜基础模型的后训练产物。 这一事件反映了OpenAI在模型命名和发布策略上的灵活调整,也暗示其在不断寻求推理训练与成本的平衡。尽管如此,OpenAI并没有秘密掩盖,只是在适应技术和市场需求时做出了不同选择。 预期中的GPT-5,传闻正是基于GPT-4.5级别的基础模型,结合更加深入的推理训练,以追求更高性能。
GPT-5不仅在模型规模上值得期待,更在推理和知识整合能力上有潜力实现飞跃。业内估计,OpenAI为了开发GPT-5将投入高达20亿美元的计算资源,等同于GPT-4计算需求的50倍。 如何分配这庞大计算资源,在预训练和推理训练之间找到最优比例,是OpenAI面临的核心难题。推测范围从20%推理训练配比到90%,每种方案背后都有不同的资源需求和技术风险。训练更大的基础模型需要预训练投入更多算力,而推理训练阶段则能够针对性提升模型的特定能力。 目前,推理训练规模与基础模型大小之间的关系尚未完全明朗。
传言推理训练对大模型更有效,因基础模型提供了更强的认知“底盘”,可以让后续强化学习更加高效。然而也有观点认为,在数据质量和奖励机制到达壁垒后,仅单纯增大模型规模未必能带来成比例的收益。值得注意的是,推理训练目前主要针对数学和编程等易于验证的任务,针对更长更复杂的自主任务的训练尚未普及,这也是未来发力的重点。 公开透明度的缺乏仍是AI产业面临的重要议题。OpenAI通过一系列保密措施,保护其商业机密,但这也使得外界难以准确评估模型风险和潜在影响。未来,随着AGI技术的发展,呼吁更多透明和监管的声音日益增强。
政策制定者、研究机构乃至公众,都希望能够更好地理解AI训练的规模、能力和安全保障措施。 除了技术路线分析,观察OpenAI模型的市场策略同样关键。定价机制反映了模型体量和性能的权衡,小型模型面向大众市场,满足普适需求;大型模型则多用于复杂任务和高端应用。蒸馏技术和推理训练的结合,有效降低了门槛,普及了智能AI的使用。 对于未来,除了GPT-5之外,更多基于推理训练和增强学习的模型创新将不断涌现。用户和开发者应关注模型可用性的提升、API稳定性和安全性,同时保持对AI伦理和监管的重视。
AI技术带来的生产力革命需要建立在负责任的技术部署和持续监督之上。 总结来看,OpenAI模型的发展是基础模型预训练、强化推理训练和模型蒸馏三者协同演变的结果。每一步都体现了计算资源、训练方法和应用需求的综合平衡。未来随着技术突破和硬件升级,GPT-5及其后续版本有望突破现有性能天花板,为各行各业带来更为智能和高效的解决方案。理解这一演进路径,能帮助我们更好地把握AI技术的未来方向,为数字化时代的创新和转型铺路。









