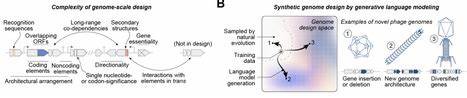
近年来,人工智能与生物学交汇催生了前所未有的研究方向,其中"基因组语言模型"代表了将自然语言处理方法应用于DNA序列分析與生成的最前沿技术。与单一蛋白质设计不同,基因组尺度的生成任务必须兼顾基因安排、调控元件、编码区与非编码区的相互作用,因此挑战更高也更具变革性。最新研究展示了利用基因组语言模型生成完整噬菌体基因组并获得可行病毒颗粒的可行性,为噬菌体设计与噬菌体治疗开辟了新的路径,同时也对伦理与生物安全提出了深刻问题。本文从概念、技术框架、实验验证、应用前景与风险治理五个角度,系统阐述基因组语言模型在生成式噬菌体设计领域的核心贡献与未来方向。 基因组语言模型本质上是通过海量序列数据训练出的生成式模型,它能在"理解"序列统计规律与进化约束的基础上,提出新的碱基排列方案。与传统基于规则或进化启发的设计方法不同,语言模型通过学习大量天然基因组样本的模式,能隐式捕捉到基因共表达、重叠编码和调控位点布局等复杂信息。
在噬菌体设计场景中,研究者使用了两代先进模型(常被命名为Evo 1与Evo 2)作为生成引擎,结合任务特化的微调与提示工程,朝着具有目标宿主嗜性和可操作性的新型基因组进行采样与筛选。 技术上,生成可行噬菌体基因组并非单靠模型采样即可完成,必须构建一系列风险可控与生物学合理的约束与评估体系。典型的工作流程包括选定目标宿主与参考模板(如长期为基础研究所采用的小型噬菌体ΦX174),对同源家族序列进行有针对性的微调以增强模型对该类噬菌体结构和功能要素的生成能力,通过短提示(prompt)引导模型在初始位置生成连贯全长序列,并在推断阶段结合多个生物信息学预测器筛除低质量或偏离目标宿主嗜性的候选。为了鼓励进化新颖性同时保证功能保留,研究者们还采用多层过滤,包括对编码密度、基因数与基因顺序(synteny)、关键表面蛋白保守性等指标的评估,从而在生成过程实现可控的"探索与保守"平衡。 这一整套计算流水线的核心优势在于能够在既有自然演化空间之外提出高质量序列候选,并在后续的实验验证中挑出少量真正具有生物学活性的样本。最近的一项研究在筛选数百条候选生成序列后,成功合成并验证出多达十数个能够在目标大肠杆菌株中完成感染和裂解周期的人工噬菌体。
这些人工噬菌体在基因组层面展现出显著的新颖性:既包括与参考模板高度保守的关键受体识别蛋白以维持宿主嗜性,也包含大量在天然数据库中未见的序列变异或新的非编码元件组合。更值得注意的是,其中若干生成体在宿主竞争实验中显示出比参考野生型更高的相对适应度,或在溶菌速率与感染动力学上具有优势。 结构学分析为理解这些生成噬菌体如何维持功能性提供了关键信息。例如对部分人工噬菌体进行冷冻电镜(cryo-EM)解析后,研究者发现某些生成体在关键结构蛋白上采用了与天然变体不同的空间构象,但仍能维持与衣壳或基因组包装相关的相互作用,这显示模型在设计时不仅改变了序列,还合理保留了必要的结构兼容性。这样的发现为研究噬菌体蛋白质间共进化与结构塑性的生物学机理提供了新的视角,也证明生成式方法能够在高维的设计空间内找到功能等价或超越天然变体的解决方案。 在应用层面,生成噬菌体具有潜在的多种价值。
噬菌体治疗作为对抗耐药细菌的有力补充,依赖于能够迅速获得具有目标宿主活性的噬菌体组合。生成式方法能够在较短时间内提供多样化、高适应性的候选库,从而加速定制化噬菌体鸡尾酒的开发并提高应对菌株演化逃逸的弹性。此外,新型噬菌体也可作为分子工具在基因传递、细胞标记或微生物群调控等合成生物学任务中发挥作用。通过结合机器学习驱动的预测与高通量筛选,未来可能实现更快的候选发现与功能优化流程。 然而,与任何改变生物体基因组的技术一样,生成噬菌体在伦理与生物安全方面的考量不可忽视。核心原则包括限制设计范围、选择安全可控的实验模型、建立多层次的治理机制与透明度。
实践中,研究团队通常通过数据集策略与模型训练策略做出初步限制,例如在预训练或微调阶段排除有害的真核病毒序列以降低模型越界生成潜在病原体的风险;在实验选择上优先使用非致病宿主与历史安全记录良好的噬菌体模板;在实验室操作层面严格遵循生物安全等级与废物处置规范。此外,推动学术界与监管机构之间的对话和制定相关指南,对于确保此类生成技术在社会化应用时的合规性与可审查性至关重要。 技术局限性方面,目前的生成工作仍受训练数据偏差、合成与组装成本、以及实验验证通量的制约。模型所学到的内容很大程度依赖于可获得的测序与注释数据,因此某些功能或机理在训练集中稀缺时难以被捕获。另一方面,将生成序列转化为可测试的生物体仍需要合成与组装基础设施,且实验筛选往往成为瓶颈。面对这些限制,未来研究可能借助更高效的体外表达系统、自动化合成平台与更精细的模型控制策略,以提升从计算到实验的整体效率。
在科研伦理与治理方面,除了必要的生物安全规范外,还需要关注开放数据与开放工具带来的双刃剑效应。生成模型与相关代码、数据的共享能加速科学进展,但也可能被滥用。为此,社区层面正在讨论分级发布、访问控制、以及在模型设计中内置使用限制的可行性方案。学界、产业与监管部门之间的合作应当集中在制定风险评估框架、明确责任主体,以及建立快速响应的审查流程,以在鼓励创新的同时最大限度降低潜在危害。 展望未来,基因组语言模型有望与其他计算与实验技术形成强有力的协同体系。一方面,结合更加精细的结构预测、进化模型与功能预测器,可以提高生成序列的成功率与可解释性。
另一方面,自动化实验平台与高通量表型测定将缩短验证周期,使生成 - 测试 - 迭代闭环更快地推进。长期来看,这类技术可能不仅用于噬菌体设计,还能扩展到更大规模的病毒工程、合成微生物群落构建,甚至对天然微生物生态系统的理解产生深远影响。 总之,基因组语言模型在生成新型噬菌体方面展示了强大的潜力:它们能够在保证宿主选择性与基因组完整性的前提下,探索天然未达成的序列创新空间,产生具备功能性的人工噬菌体并带来可观的表型改进。与此同时,这一领域也迫切需要健全的风险管理、透明的治理机制及跨学科的社会对话,以确保技术进步惠及公共卫生与科学研究而不被滥用。随着模型能力、合成技术与实验平台的不断成熟,生成式基因组设计有望成为合成生物学与精准微生物治疗的重要组成部分,但其发展必须在严格的伦理与安全框架下稳妥推进。 。