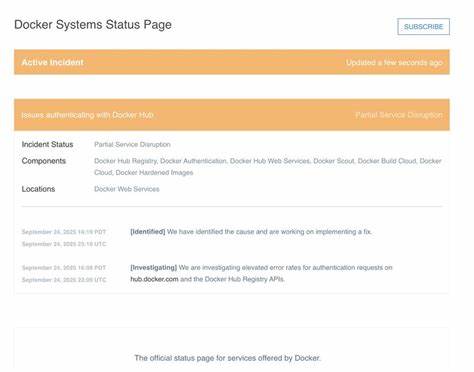
Docker Hub 作为全球最广泛使用的容器镜像托管平台,是许多开发者和企业日常工作中的关键组成部分。然而,近期 Docker Hub 再次出现宕机,引发了广泛关注与讨论。服务的不可用不仅影响了容器镜像的拉取与上传,还对持续集成、部署流程带来了显著影响。了解 Docker Hub 宕机背后的原因及其带来的广泛影响,对于构建更具韧性的开发环境至关重要。 Docker Hub 的核心功能是为数以亿计的用户提供稳定可靠的镜像存储与分发服务。其官方镜像库包括诸如 Python、Nginx、Node.js 等众多流行语言和框架的基础镜像,方便用户基于这些镜像开发应用。
Docker Hub 还提供私有仓库、镜像自动构建和安全扫描等增值功能。高度依赖 Docker Hub 的现代开发流程因其宕机而陷入瘫痪,给敏捷开发和快速迭代带来挑战。 造成 Docker Hub 宕机的原因多种多样,从网络攻击、硬件故障、软件更新不当,到内部配置错误,每一种原因都可能导致服务中断。平台持续扩展的用户规模与流量也增加了系统负载,任何微小的系统缺陷都可能引发连锁反应。尤其在高峰时段,系统压力骤增可能导致响应延迟甚至完全失效。此外,Docker Hub 作为云服务的一部分,也受到云基础设施稳定性和第三方服务的影响。
对于使用 Docker Hub 的开发者来说,镜像无法拉取意味着应用构建和部署过程受阻。CI/CD(持续集成/持续交付)流水线依赖稳定的镜像获取,任何阻断都会加剧开发迭代的滞后。企业生产环境若直接依赖 Docker Hub 镜像,一旦宕机便可能导致生产服务不可用,影响业务连续性和用户体验。同时,镜像上传受阻会阻碍开发团队分享和发布最新版本的容器镜像,降低团队协作效率。 面对 Docker Hub 的频繁宕机,采取多层次的应对策略变得尤为重要。首先,建立本地私有镜像仓库成为许多企业首选,通过缓存镜像减少对外部仓库的依赖,保证核心镜像能够及时访问。
其次,合理利用多镜像仓库结构,结合 Docker 官方镜像、第三方镜像源以及本地镜像,降低因单一仓库故障带来的风险。其次,完善镜像版本管理,确保某一版本出现问题时可以迅速回滚或切换。 在镜像管理之外,自动化流水线应具备容灾和重试机制。CI/CD 工具链中增加镜像拉取失败的重试策略,利用镜像缓存和镜像仓库镜像代理等技术手段,增强系统弹性。对于依赖 Docker Hub 的云原生应用,还可考虑多区域、多云方案,通过跨区域容器镜像镜像同步,保障不同地理位置环境的稳定访问。 开发者自身也应关注最佳实践,编写更加可靠的 Dockerfile,减少对外部资源的实时依赖。
例如,使用固定版本镜像而非随时更新的最新标签,避免不确定性的升级导致部署失败。另外,详细监控镜像拉取和构建环节的日志,及时捕获并处理异常,有助于缩短故障影响时间。 Docker 社区和 Docker Inc. 本身也在不断提升 Hub 的稳定性和安全性。加强基础设施的弹性设计、优化内容分发网络(CDN)、采用微服务架构分散风险,是技术团队持续改进的重点。同时,官方对事件的透明通报和用户反馈机制,有助于建立用户信任和提供及时解决方案。随着技术的进步,自动化运维和智能预警功能将在保障关键服务稳定方面发挥更大作用。
与 Docker Hub 紧密相关的生态系统也受到了服务中断的冲击。基于镜像的Kubernetes集群、Helm包、DevOps流水线、云原生平台等均需依赖镜像的稳定下载。因而,使用者不仅需要关注 Docker Hub 的状态,还应建设完善的多供应商镜像策略和容器管理体系,加强对镜像生命周期的管理和审计。 总结而言,Docker Hub 再次宕机提醒所有容器用户不得忽视外部服务带来的不确定性。一个高效且可靠的容器生态,需依托稳定的镜像仓库,但更需要开发者和企业具备多层保障能力和灵活调整机制。通过构建本地镜像仓库、实施多镜像源策略、完善 CI/CD 容灾设计,以及关注 Docker 官方的改进动态,用户可以有效减少因 Docker Hub 宕机带来的影响,确保开发和生产环境的持续稳定。
未来,随着容器技术的不断发展和多元化镜像服务的兴起,开发者和企业将拥有更多选择,打造更加健壮的云原生应用基础设施。 。