近年来,随着人工智能领域的迅猛发展,大规模语言模型(LLMs)如LLaMA、GPT系列逐渐成为自然语言处理领域的重要工具。然而,随之而来的模型复杂度和庞大参数量也带来了巨大的计算与存储负担,限制了这些模型在边缘设备和资源受限环境中的实际应用。为了克服这一难题,模型量化技术成为研究热点,尤其是4-bit低位宽量化受到了广泛关注。量化能够显著减少模型内存占用和计算资源,但往往会导致模型性能下降,特别是在处理那些激活值中存在极端离群点时问题尤为严重。本文聚焦于一种新兴的量化方法——SmoothRot,该方法巧妙地结合了通道级别的缩放与旋转操作,专门解决LLM在量化过程中面临的激活异常值问题,提升了量化后的模型性能和稳定性。 激活异常值在量化中的挑战是众所周知的。
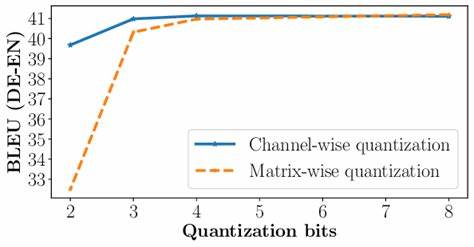
在传统量化方法中,统一的缩放因子难以针对各个通道中不同的数值分布进行有效调整,导致某些通道异常激活值被“放大”,从而降低了整体量化的精度和效果。SmoothRot引入一种基于Hadamard变换的旋转手段,结合通道特定的缩放策略,有效地重新分布激活值,使极端离群值变得更平滑和量化友好。这种创新的处理方式不仅降低了激活异常对量化误差的影响,还确保了模型在保持低位宽的同时,性能损失明显减少。 从实际效果来看,SmoothRot技术在多个主流LLM模型中展示了强大的适应能力。以LLaMA2 7B、LLaMA3.1 8B以及Mistral 7B为例,该方法能够减少量化模型与原始FP16模型间性能差距约10%到30%,涵盖语言生成和零样本推理任务。这种改进提升了量化模型在下游应用中的实用性和可靠性,同时不会引入额外的推理延迟,充分满足实时性的业务需求。
为何SmoothRot能够取得如此突破性的成果?关键在于它创新地将数学变换与深度学习量化需求相结合。Hadamard变换作为一种易于计算的正交变换工具,能够将数据投影到新的坐标系中,使激活的幅度分布更加均匀;同时,通道维度的独立缩放调整尊重了每个通道的数值特性,避免了莫须有的共用缩放比例带来的量化误差。两者的合力使得4-bit量化不再单纯依赖原始数值的固定范围截断,而是通过结构化的线性变换,将异常激活“平滑化”,极大缓解了量化噪声。 从技术实现角度,SmoothRot作为一种后训练量化(PTQ)方法,无需模型重训练,大幅降低了部署门槛和计算成本。这对于实际工程应用尤为重要,开发者和企业无需投入高额时间和资源重新调优模型,即可享受到量化带来的计算优势。结合现有开源框架,SmoothRot的集成和调用也变得十分便捷,支持快速将已有大型模型转换为高度压缩且性能优越的低位宽模型版本。
未来,随着硬件加速器对低位宽计算的支持日益丰富,量化技术必将成为推动AI模型普及和落地的核心基石。SmoothRot的创新思路不仅在标准LLM量化中具备价值,更有望扩展到多模态模型和其他深度神经网络结构中,解决激活分布复杂多变带来的挑战。同时,结合自适应量化、混合精度以及多尺度优化等先进策略,SmoothRot的理论与应用潜力将进一步被挖掘。 综观当前人工智能模型发展趋势,算法创新与硬件快速演进相辅相成。通过结合通道级缩放与旋转变换,SmoothRot为量化领域注入了新活力,为在有限计算资源下实现大规模语言模型的高效推理提供了有力工具。它不仅推动了量化技术的实际落地,也为更多轻量化AI应用场景打开了大门。
随着更多研究者和开发者关注并采纳类似方法,未来AI模型的廉价、快速、高质量推理必将成为现实,助力人工智能技术更加广泛服务于社会各行各业。