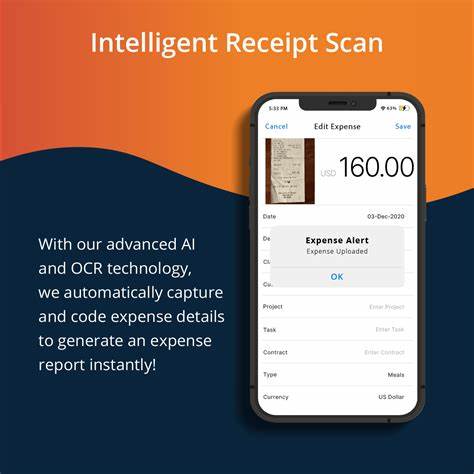
在数字化办公和财务管理日益普及的背景下,自动化识别发票信息成为提升工作效率的重要途径。Navan作为一款智能企业费用管理应用,其发票扫描功能因能快速准确获取消费总金额而备受关注。本文将解析如何基于机器学习模型,尤其是SmolDocling-256M-preview模型,复刻Navan类似的发票识别功能,进而实现自动提取发票上的"总金额",帮助开发者打造便捷且高效的费用管理体验。首先,理解发票扫描功能的核心在于图像识别和自然语言处理技术的结合。传统方式需要人工逐项输入消费信息,不但耗时且易出错。而通过图像文本模型,输入发票图片及针对性的文本查询,模型能直接输出所需信息,如总金额,极大节省用户时间。
SmolDocling-256M-preview是一款图像-文本-文本模型。它通过预训练海量的图像和文字对,能够根据输入的图像内容并结合对应的问题提示,准确生成文本答案。虽然其参数量仅为2.56亿,属于轻量级模型,但在多次实际测试中显示了良好的识别效果。实际测试中,将不同来源和风格的发票图像输入该模型,并以"发票的总消费金额是多少?"为查询,得到了准确的金额输出。特别是在数字化电子收据截图和品牌商店发票上,模型表现尤为稳健。除了查询设计,提示词的优化对结果准确度影响显著。
例如,仅提出简单问题时模型可能误判或读取不准确的金额;加入明确的上下文要求,"请在带有'TOTAL'文字的附近寻找总金额",则能明显提升识别正确率。此类策略有效解决了金额字段附近有其他数字干扰的问题。然而,模型仍面临一定限制。针对字体较小、布局复杂或总金额表达不规范的发票,识别结果准确率有所下降。此外,部分本地超市发票因格式多样或信息密集,模型易产生错误或语义混淆。基于测试数据,SmolDocling在执行发票总金额提取任务时,约有80%的准确率。
虽然不能确保每次都完美,但对于企业日常报销,已经明显优于完全人工输入。结合后续人工校验,能极大提升整体工作流效率。除了模型精度,推断速度同样重要。SmolDocling在普通笔记本硬件环境下,每张发票图像的处理时间保持在2至3秒之间,满足多数应用的响应需求。若配合更强大的专用硬件,速度可进一步提升至0.35秒,实现瞬时交互体验。未来为寻求更高准确度和更复杂的发票信息提取,开发者可考虑使用参数量更大的模型,或结合多模型融合技术,同时优化提示词和数据增强手段。
此外,将文本后处理和规则校验嵌入系统,能有效补偿模型误差。最终,集成上述技术,软件产品能够实现从拍摄或上传发票照片,到自动解析出总金额,极大缓解用户手动输入负担,减少出错几率,提升报销速度。面对市场上多样化发票格式和复杂消费场景,智能发票识别的价值日益凸显。许多企业正通过此类技术改善费用监管与财务透明度,推动数字化转型落地。总的来看,借助SmolDocling模型及合理的查询设计,轻松实现自动识别总金额的功能成为可能。虽非完美,但足以支持大多数主流发票格式。
同时,结合不断优化的技术手段及业务流程,相关功能未来有望实现更高的准确率和更广泛的适用性。开发者在设计类似Navan的发票扫描系统时,应重点关注模型选择、提示词设计和推理性能,确保用户体验顺畅。此外,合理引入人工验证机制,既能保障数据质量,又不会牺牲自动化带来的便捷。整体来看,智能发票扫描不单是技术挑战,更是提升企业运营效率和用户满意度的关键利器。持续关注行业最新机器学习模型与图像识别技术的进步,将助力构建更智能化、准确且高效的费用管理生态。 。









