随着人工智能技术的飞速发展,大型语言模型(LLM)在信息处理和内容理解方面的能力日益增强,成为推动数字化进程的重要力量。然而,语言模型在解析和利用复杂网站信息时,面临着上下文容量有限和内容提取效率低下的挑战。为了克服这些瓶颈,一个名为/llms.txt的标准文件应运而生,旨在帮助语言模型更好地使用网站资源,实现信息的精准抓取和高效利用。 /llms.txt文件是一种基于Markdown格式的轻量级文本文件,通常放置于网站根目录下,用以向语言模型提供网站背景信息、核心内容摘要和相关资源链接。它不依赖于繁杂的HTML结构,剥离网页中的导航、广告和多余的脚本代码,专注于为模型提供简洁、结构清晰的文本内容。这种设计不仅提升了语言模型读取网站内容的效率,也极大降低了解析复杂网页时的误差。
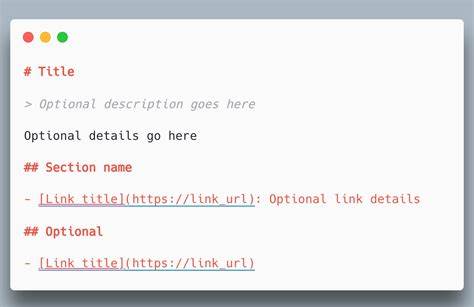
该文件结构严谨,通常以主标题(H1标记)开头,明确网站或项目名称,紧接着是一个块引用,简洁扼要地介绍该网站的核心信息和使用说明。随后,可以包含详细的文本内容、说明段落以及若干二级标题(H2标记)分隔的资源列表。每个资源列表下面配有链接和简短注释,帮助语言模型准确定位相关的细节内容。特别值得一提的是,/llms.txt文件支持可选的“Optional”部分,用于标注次要或补充资料,给予模型根据需求选择优先读取内容的自由。 这种标准格式相较于传统的robots.txt和sitemap.xml文件,体现了不同的设计理念及使用场景。robots.txt主要用于告诉搜索引擎允许抓取或禁止访问哪些网页,保证网站安全和流量合理分配;sitemap.xml则是面向搜索引擎,列出网站所有可索引页面,辅助蜘蛛爬行并提高SEO效果。
相比之下,/llms.txt侧重于为语言模型提供经过策划和浓缩的内容,减少无关信息带来的干扰,帮助模型在有限上下文中提取最大价值。 /llms.txt文件的诞生背景源于大型语言模型处理网站内容的瓶颈。由于模型的上下文窗口有限,直接输入整站HTML结构不仅高耗费计算资源,还会带来信息冗余和语义模糊。通过提前准备简洁规范、格式统一、富含重点信息的/llms.txt文件,模型可以快速获取网站核心结构、功能介绍、API文档、示例代码等关键信息,实现快速响应并提升生成内容的准确度。 目前,以FastHTML项目为代表的一些开源社区已经开始实践/llms.txt标准。在FastHTML的网站中,不仅提供了/llms.txt文件,还在其相关文档页配备了对应的.md格式文件,这些Markdown文件通过命令行工具自动生成,并能根据需求生成包含或不包含可选链接的上下文文件,极大地方便了语言模型的使用。
此外,多款主流网站生成工具和框架也陆续推出支持/llms.txt的插件和集成方案,让更多开发者能够轻松将该标准引入自己的工作流程。 /llms.txt的应用意义不仅限于技术文档或开发者社区。商业网站、电商平台、教育机构甚至个人博客都能通过这种方式,明晰地传达网站结构和核心内容。例如,电商网站可以通过/llms.txt文件,向智能客服或推荐系统提供商品描述、促销政策及配送信息,提高客户体验和服务效率;高校官网可以利用该文件集中展示课程目录、师资介绍及校内活动,方便智能问答系统准确回答用户提问。 值得关注的是,/llms.txt文件的语法基于Markdown,既保证了人工可读性,也便于通过正则表达式或解析器等传统编程方法进行自动化处理。这种设计体现了实用主义精神,兼顾人机双向友好,使得维护和更新文件十分便利,且便于快速迭代和功能拓展。
今后,随着社区参与度的提升和标准持续完善,/llms.txt或将成为网络信息架构中的重要组成部分,促进多样化语言模型的广泛应用。 如何创建高质量的/llms.txt文件同样关键。内容应简洁明了,避免复杂术语和模糊表述,链接须附带简短描述,方便模型理解资源的性质和用途。此外,定期运行解析工具进行功能检测,检验语言模型对文件内容的理解和问答效果,有助于不断优化文件结构和可读性。通过这些举措,网站运营者能够有效提升AI助手和智能应用的表现,赢得更多用户认可和信任。 尽管/llms.txt的规范尚处于不断成熟阶段,但其潜力不可小觑。
未来,我们有理由期待它能与现有网络标准形成互补,带来更人性化、更智能化的网络交互体验。尤其是在多模态AI和智能代理日渐普及的今天,网站通过/llms.txt向语言模型提供结构化、权威的内容支持,将极大地推动信息检索和自动问答技术的进步。 总结来说,/llms.txt文件代表了一种创新思路——为语言模型量身定制的网站文本内容格式,旨在解决复杂网页信息处理的痛点,提升模型推理和回答的效率与准确性。它不仅顺应了AI智能化发展的趋势,也为网站管理者提供了新的内容管理思路。随着技术推广和生态完善,/llms.txt有望成为智能信息时代的标配工具,推动人机交互迈向崭新的高度。