在人工智能和机器学习技术迅猛发展的推动下,推荐系统已成为互联网服务中不可或缺的一环。面对海量且异构的用户行为数据,传统模型面临着计算资源瓶颈和建模精度的双重挑战。近期,生成式推荐框架(Generative Recommender Framework,GR)的崛起引入了新的思路,尤其是结合层级顺序转换器(Hierarchical Sequential Transducers,HSTU)与上下文并行性(Context Parallelism,CP)技术,极大提升了推荐系统对长序列历史的建模能力与计算效率。本文将系统探讨这一前沿技术的核心内容及其对推荐领域的深远影响。首先,需要理解的是推荐系统所面临的复杂数据环境。用户在诸多平台和场景中的交互数据量庞大且类型多样,从点击、浏览、收藏到购买等行为,均展现出高度非平稳性和稀疏性。
这对模型提出了在保持高准确率的同时,具备高效处理能力的要求。层级顺序转换器正是在此背景下应运而生。HSTU通过引入多层次的注意力机制,结构化地表达长时间跨度内的用户行为序列,具备对高基数、非平稳性的优越适应性。其设计巧妙地结合了序列的层级特征,补足了传统Transformer架构在长序列处理中的短板,能够从更丰富的上下文环境中提取有效信息。尽管HSTU拥有强大的表达能力,但随着用户行为序列长度的增长,激活内存消耗急剧上升,制约了模型在工业级数据上的扩展性。为解决这一瓶颈,上下文并行性技术应运而生。
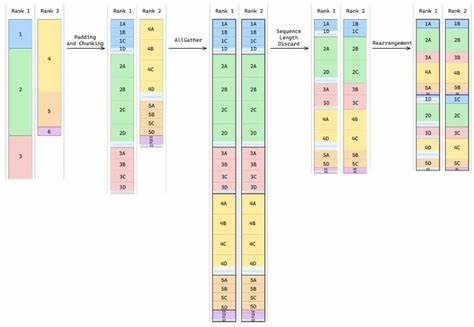
CP通过沿序列长度维度在多GPU间分布计算任务,有效降低单节点内存压力,成为应对长序列计算挑战的有效手段。然而,推荐系统中的输入往往以锯齿状张量(jagged tensors)形式存在,这带来了实现上下文并行的额外困难。常见的Transformer模型处理的是规则矩阵格式,而锯齿状张量结构中每个样本长度不一,直接分割带来复杂的内存分配和通信协调问题。针对这一难题,最新研究提出了支持锯齿状张量的上下文并行解决方案。该方法在HSTU架构中加入了专门的分片机制,实现了将异构长度的用户交互数据合理划分到多GPU,并同步执行注意力计算操作。经过优化的通信策略和内存管理算法不仅保证了数据一致性,也极大提升了整体训练与推理效率。
实际实验结果显示,该技术可以将支持的用户交互序列长度扩展至原有的5.3倍,并且结合分布式数据并行(Distributed Data Parallel,DDP)时,整体计算性能提升了约1.55倍。这对模型捕捉用户长期兴趣演变及多样化行为模式具有重要意义,使得推荐系统更加精准且响应迅速。层级顺序转换器与上下文并行性的结合,不仅优化了算法性能,还为生成式推荐框架在工业实践中的落地提供了坚实保障。生成式推荐相较传统判别式方法,能够更灵活地建模用户行为序列的复杂依赖关系,生成个性化推荐结果。借助高效的并行计算能力,使得系统不仅支持更长时间的用户历史数据,也能实时更新和响应,提升用户体验和商业价值。展望未来,随着计算硬件性能的持续提升及算法理论创新,基于上下文并行性的层级顺序转换模型有望在多模态推荐、跨域推荐等复杂任务中发挥更大作用。
同时,对于模型架构本身,如何进一步减少内存占用、加快推理速度、提升鲁棒性,也将是研究重点。结合自动调优技术和动态资源调度,有望实现极致的计算资源利用率。另外,数据隐私保护和模型解释性也是值得关注的方向。通过引入联邦学习和可解释模型设计,既满足个性化推荐需求,又兼顾用户隐私及平台合规要求。总的来说,层级顺序转换器中的上下文并行性技术标志着推荐系统技术升级的重要里程碑。它巧妙解决了长序列记忆瓶颈,提升了生成式推荐的准确率和扩展性,推动了推荐领域智能化应用的深度发展。
随着相关研究不断深入,相信此类技术将广泛应用于电商、社交媒体、内容分发等多个场景,打造更加智能、个性化的数字体验生态。 。