随着人工智能技术的飞速发展,语言模型在自然语言处理领域的应用日益广泛。从智能助理到自动内容生成,语言模型承担着越来越多关键任务。然而,伴随其能力提升,模型的事实准确性问题日益突出,虚假回答与信息错误风险逐渐成为限制其应用的瓶颈。为此,衡量和提升模型的事实性成为学术界与工业界的核心目标。SimpleQA Verified应运而生,作为一个专门针对大型语言模型短文本事实性的衡量基准,它弥补了先前相关数据集存在的不足,推动了模型性能的真实进步。SimpleQA Verified基于OpenAI早期推出的SimpleQA数据集,但经过严格的多阶段筛选与优化,解决了原基准中的标签噪音、主题偏差及重复冗余等问题。
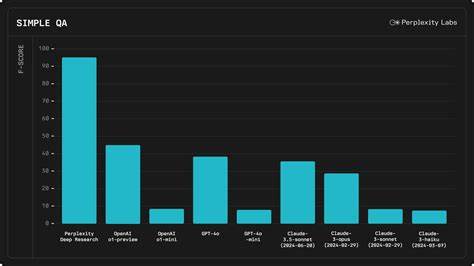
该数据集包含1000条精心设计的测试题目,涵盖广泛的话题且难度适中,保证了对模型事实知识的有效考察。Multi-stage filtering流程不仅消除了重复问题,还实现了主题均衡和信息源对照,确保每条测试题目都拥有可靠的参考答案和标签精度。此外,SimpleQA Verified针对自动评分机制进行了调整,提高了评估结果的公正性与鲁棒性。该基准的推出,为研究人员和开发者提供了一个更为可靠的工具,可用于衡量模型在参数记忆中存储并正确输出事实的能力。通过基准测试,现有最先进的模型表现一目了然。根据最新实验,Google旗下的Gemini 2.5 Pro在该基准上的F1分数达到了55.6,领先于诸如GPT-5等多款竞品模型,展示了其在真实世界知识准确性上的优势。
这一成果不仅体现了SimpleQA Verified在挑选测试题目的严谨性,也反映了模型技术进步的实际效果。SimpleQA Verified的重要性还体现在其为AI社区提供了一个标准化、透明、可复现的评测框架。此前,模型评估多依赖于不完善或存在偏差的数据集,导致科研成果难以直接对比甚至产生误导。通过公开数据集、评估代码及排名榜,SimpleQA Verified营造了一个开放共享的生态环境,促进了技术沟通与创新。面对日益复杂的信息环境,模型的知识存储和泛化能力至关重要。SimpleQA Verified通过精准定义参数化知识事实性,为语言模型未来的发展路线指明方向。
在提高语言理解深度的同时,也为减少模型"幻觉"现象提供了保障。无论是学术研究还是商业部署,围绕SimpleQA Verified的持续优化和应用都将显著提升系统的可信赖度与用户体验。这一基准代表了AI领域在确保生成内容真实可靠方面迈出的关键一步。展望未来,SimpleQA Verified有望与更多真实世界场景相结合,进一步复杂化测试内容,覆盖多语言、多领域,促进多模态知识的融合评测。结合类似的事实性验证技术,相关工具将帮助开发更智能、更稳健、更可信的语言模型。总结来看,SimpleQA Verified不仅是一个简单的数据集合,而是驱动人工智能语言技术突破的基石。
它推动了研究者对参数知识理解的深化,促进了模型事实性检测方法的革新,也引导业界构建更加真实可信的智能应用环境。随着这类基准的广泛应用,我们有理由期待,未来的AI系统将在保证内容真实性的基础上,释放出更强大的创新潜力,助力数字社会迈向更加美好的未来。 。