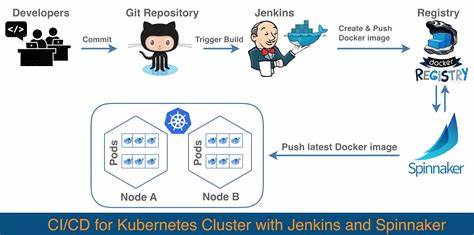
随着云计算和容器技术的不断普及,Kubernetes已成为主流的容器编排平台。尽管许多团队能够顺利完成Kubernetes的首次部署,但在系统上线后的日常运维管理,即通常所说的“Day 2”运营阶段,仍然面临诸多挑战。第一天的部署更多关注集群的搭建和应用的发布,而Day 2运营则涉及系统的稳定性保障、高可用性布局、灾难恢复以及持续的监控和优化。本文聚焦于Kubernetes Day 2运营的关键问题,结合行业实践,分享当前在高可用架构设计、灾难恢复方案以及跨集群观察性建设方面行之有效的经验,为相关运维人员提供有价值的参考。 Kubernetes的Day 2运营中首要面对的问题是如何实现系统的高可用性,尤其是针对云供应商区域性故障的防范。Kubernetes默认支持主节点的高可用部署,保证控制平面的稳定性,但在节点分布上若全部集中于单一区域,则极易受该区域的网络或硬件问题影响,导致服务整体瘫痪。
通过构建跨区域的多可用区部署,能够在单一区域出现故障时,其他区域自动接管流量,保证服务持续可用。实践中,利用云厂商提供的多可用区集群,以及负载均衡器的智能流量路由能力,实现对多个集群或节点的动态调度。此外,采用联邦集群(Kubernetes Federation)实现多集群之间的统一管理,进一步增强了容灾能力和运维灵活性。灾难恢复(Disaster Recovery,DR)是Day 2管理的重要组成部分。成熟的灾难恢复方案不仅能够快速响应系统故障,还能最大限度地减少数据丢失和业务中断时间。在Kubernetes环境中,采用定期备份etcd数据和应用配置信息、持久卷(Persistent Volume)快照、以及镜像仓库异地同步,是保障集群状态恢复的重要方法。
结合自动化脚本和CI/CD流水线,在灾难发生时能够快速恢复集群及其服务,有效提升运维效率。实现全链路的Observability(可观察性)是确保系统健康运行的另一关键环节。由于Kubernetes集群往往包含了大量的微服务、网络和存储组件,单一维度的监控难以满足运维需求。当前流行的做法是通过搭建集成Prometheus、Grafana、ELK(Elasticsearch、Logstash、Kibana)等工具的监控架构,实现对集群状态、应用性能、日志信息和网络流量的多维度采集与可视化分析。此外,结合分布式追踪(Distributed Tracing)技术如Jaeger或Zipkin,可以定位跨服务调用的性能瓶颈和异常,为故障排查提供精确线索。跨集群的观察能力同样重要,尤其是在大型企业采用多集群策略时。
通过统一采集和分析多个集群的监控数据,运维团队能够全面掌握整体环境的运行状况,及时识别潜在风险。Security(安全性)在Day 2运营中不可忽视。多租户环境下的访问控制、网络策略以及镜像安全扫描等措施是防范安全事件的基础。利用Kubernetes 内置的RBAC角色控制和网络策略,以及结合第三方安全产品,构建多层防护体系,保障集群免受攻击。实践中,定期更新和审计集群组件,及时修复安全漏洞,是维系系统长久健康的关键。自动化在Kubernetes Day 2运营中的价值愈发凸显。
无论是集群升级、应用滚动更新,还是故障恢复流程,借助CI/CD和GitOps的理念,实现多环节自动化极大提升了效率和可靠性。自动化即代码,使运营变得可复现且易管理,同时降低人为操作失误。运维团队可以将更多精力聚焦于策略优化和异常预警,提升整体运维水平。社区和生态系统的不断发展也为Day 2运营提供丰富资源和支持。通过开源工具和第三方服务,团队能够快速搭建适合自身业务的运维体系。积极参与社区交流,学习他人经验,结合实际需求创新优化,是保持领先优势的重要途径。
总结来看,Kubernetes Day 2运营虽然复杂且充满挑战,但随着相关技术和实践的成熟,已经有大量行之有效的方法能够帮助运维团队保障系统高可用性、实现可靠灾难恢复及提升观察能力。关键在于结合业务需求,合理设计多可用区部署方案,落实自动化和安全保障措施,构建全面系统的监控和告警体系。通过持续学习和改进,企业能够最大限度发挥Kubernetes的强大功能,保障业务稳定高效运行。