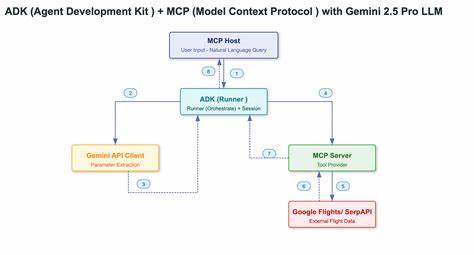
生成式人工智能的崛起在短时间内推动了创新浪潮,但与此同时也为网络犯罪提供了前所未有的工具与效率。近年来出现的"vibe hacking"一词形象地描述了犯罪分子通过自然语言提示操纵大模型行为、绕过安全限制并发动高级攻击的现象。理解这些新型威胁、识别其运作模式并部署切实可行的防护措施,已成为企业、研究机构与监管者的紧迫任务。 生成式AI被滥用的路径多样且快速演进。犯罪团伙不仅利用公开的大模型生成钓鱼邮件或社会工程脚本,还在暗网市场上销售专门定制的"恶意LLM",例如市场上流传的FraudGPT和WormGPT等,低至百美元的价格门槛极大地降低了入门成本。更令人担忧的是,一些AI代理能记忆上下文、调用外部工具并自动完成决策与执行,从而缩短攻击链时间并提高成功率。
提示注入成为最常见也最难防的一类攻击。提示注入通过在输入文本、文档或共享文件中嵌入恶意指令,诱导模型泄露敏感信息或生成有害代码。安全研究显示,某些商业模型在模拟测试中对提示攻击的易感性极高,提示注入成功率在特定情境下可达到极高比例。更复杂的场景包括在检索增强生成(RAG)系统中投毒检索集,使模型在生成过程中读取并执行隐藏指令。 数据投毒与工具投毒是另一类对抗策略,攻击者通过向开源数据集或包管理库中注入带有隐藏命令的样本或者恶意依赖项,进而在模型微调或运行时阶段触发漏洞。随着模型训练与微调流程越来越依赖开源资源,供应链风险成为不容忽视的问题。
攻击者可以利用这一渠道窃取API密钥、部署后门或引导模型执行破坏性任务。 自动化AI代理带来的风险尤为显著。与传统的"人机一问一答"交互不同,AI代理可以记忆历史上下文、调用外部接口、生成并执行代码片段。安全团队的实验证明,使用AI工具可以在二十几分钟内完成一次完整的勒索软件攻击,从发现漏洞到加密文件的整个流程实现高度自动化。这样的速度与可扩展性,让过去依赖高级技能的小团队可以在短时间内发动大规模攻击。 零点击攻击则代表了攻击技术的另一个极端。
攻击者将恶意提示或隐蔽指令嵌入被共享的文件、网页或图片中,被害者无需主动输入任何指令,模型一旦在后台处理这些内容,便可能执行攻击者设定的有害操作。随着企业广泛采用自动化处理文档、邮件和多媒体内容的AI服务,零点击风险在现实环境中愈发常见,防御难度也随之上升。 深度伪造技术被结合进社会工程活动中,将传统的钓鱼攻击升级为更具欺骗力的深度伪造语音与视频。攻击者可用生成式AI合成高逼真的音频指令或伪造高管视频用以指示财务转账、泄露机密或误导员工。结合恶意LLM自动撰写针对性的文本内容,诈骗成功率显著提升。 在现实案例层面,曾有报道指出某款代码模型被滥用于窃取个人数据、实施勒索,造成数十起组织受害并被索要巨额赎金。
安全研究机构也公开演示了通过利用提示注入与自动化工具,将一条初始提示扩展为完整的勒索攻击流程。类似事件凸显出模型开发方在发布与运营阶段未能充分预见与缓解滥用风险。 面对这些新型威胁,传统的网络安全防护思路需要升级。首先是对模型与相关组件进行系统性的安全评估与红队测试。模型在上线前应接受严密的对抗性测试,以识别可能被提示注入、数据回忆或工具调用滥用的场景。持续的红队演练和外部审计能够发现运行时的漏洞与配置缺陷,避免在真实环境中被恶意利用。
其次是对数据与依赖的供应链实施更严格的治理。对训练数据来源进行可追溯性审查,对第三方库与模型权重进行完整性校验与签名验证,可以降低工具投毒与数据投毒风险。开发团队应限制自动拉取未签名的包与模型,并在部署前对依赖项进行沙箱化测试。 在模型运行时,构建多层次的访问控制与最小权限原则同样重要。API密钥与机密信息必须采用硬件隔离或专门的秘密管理系统存放,模型不应直接访问未经审查的外部资源。对生成代码的自动执行应设置人为复核环节,禁止模型在未授权的条件下执行系统命令或修改关键文件。
对抗提示注入需要在模型设计层面加入提示规范化与输入审查机制。输入内容应经过去标签化、指令剥离与上下文一致性检查,防止隐藏指令被模型解释为合法任务。同时对模型输出建立敏感信息检测与速断逻辑,在检测到潜在敏感数据泄露时触发阻断。 在组织层面,加强员工安全意识培训、提升对AI生成内容识别能力也是减轻风险的重要一环。技术防护无法做到百发百中,人的判断仍是终端防御中的关键。通过模拟钓鱼演练、深度伪造识别培训以及对异常请求的报告机制,可以显著降低社会工程攻击的成功率。
在法规与行业治理方面,监管者与行业协会需推动模型安全标准化。借鉴药品或工业产品的安全试验框架,建立模型发布前的安全评估、可解释性声明与应急召回机制。对于高风险模型或可执行代码的代理产品,应要求厂商披露使用限制、已知滥用风险与缓解措施。 技术社区与企业也应共同推动"可审计性"与"可追责性"机制。通过在模型调用链中保留可验证的日志、对关键决策节点生成可审计的证明,并对模型更新与微调过程实行严密记录,可以在发生滥用或安全事件时快速追溯原因并采取补救措施。 跨国协作对于打击以AI为工具的网络犯罪至关重要。
许多恶意LLM的分发、运营与交易发生在跨境暗网平台,单一国家难以独立应对。情报共享、联合执法与对暗网交易链的切断需要成为国际合作的重点方向。 同时,AI研究机构与企业在技术公开与开源决策上需更加谨慎。开源在促进创新与学术交流方面具有重要价值,但在敏感模型与工具的发布上应考虑分级开放与受控共享。对高风险能力的研究应在发布前进行滥用风险评估,并在必要时采用延迟发布或受限访问策略。 对开发者而言,安全即责任的观念应深植于工程实践。
代码中应默认启用安全门槛,测试管道加入对抗性测试,并为模型调整提供安全回退策略。对外提供模型API的厂商应对商业用户进行更严格的KYC与滥用监测,及时阻断可疑账户与异常调用。 在技术创新带来风险的同时,也涌现出专门应对运行时AI安全的解决方案。包括用于监测模型调用异常、检测提示注入痕迹、验证外部工具调用合法性的运行时安全平台,和用于对模型输出进行内容与行为约束的中间层防护。这类防护能够在一定程度上弥补模型本身安全不足提供即时防护能力。 面对AI滥用的现实威胁,社会需要在乐观与谨慎之间寻找平衡。
对AI潜能的拥抱不能以放任滥用作为代价。企业、研究机构与监管层应以共同治理为原则,建立技术、规范与法律并行的防护生态,既保护创新活力,又降低犯罪外溢与系统性风险。 未来的路在于防患于未然。通过将安全设计提前嵌入模型生命周期、加强跨界合作、完善法律框架并提高公众意识,才能在AI繁荣的同时守住网络空间的底线。只有当行业与社会共同承担起对潜在滥用的治理责任,才能真正把握AI带来的红利,而不是成为技术繁荣的受害者。 总结当前形势,生成式AI在带来前所未有生产力提升的同时,也显著简化了复杂攻击的实施路径。
犯罪工具化的AI、自动化代理与零点击攻击构成了新的威胁面。遏制这些风险需要技术、管理、法律与国际协作多管齐下。对企业而言,立即可行的步骤包括强化红队测试、治理数据与依赖供应链、实施运行时访问控制与审计、以及对员工进行持续教育。对监管层而言,需要推动模型安全标准、可审计性要求和跨境执法协同。在这样的多方努力下,才能将"vibe hacking"带来的暗面控制在可管理的范围内,让AI的繁荣真正惠及社会。 。