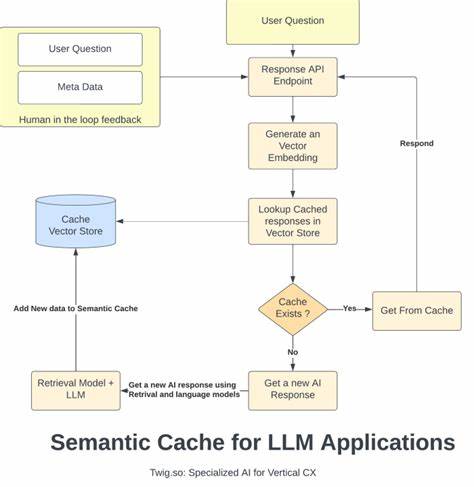
随着人工智能技术的不断进步,大型语言模型(LLM)如OpenAI的GPT系列、Anthropic等逐渐成为智能应用的核心引擎。然而,频繁调用这些语言模型不仅带来较高的计算成本,同时也存在响应延迟的问题,严重影响用户体验和系统效率。在这一背景下,语义缓存技术被提出以解决上述难题。Semcache作为当前领先的语义缓存解决方案,通过语义匹配机制,实现对LLM请求的智能缓存处理,极大地提升了语言模型的使用效率和响应速度。Semcache不仅支持主流的LLM API,还以其灵活的架构和无缝集成能力,成为众多企业和开发者优化语言模型调用的重要工具。Semcache的核心优势来自其深度的语义理解能力。
传统缓存技术往往基于精确匹配规则,仅能存储和返回完全相同的请求及其结果,这种传统方式在文本表达多样性极强的语言模型应用中显得力不从心。而Semcache采用先进的语义匹配算法,能够识别不同但语义相近的查询请求,并映射至缓存中的相关响应。举例而言,用户可能以多种不同表述方式询问同一问题,如“法国的首都是什么?”和“法国的首都城市是哪个?”,Semcache通过语义分析识别这两者本质上的信息需求一致,从缓存中快速返回此前计算过的答案,无需再次调用后端语言模型,大幅降低了重复计算量。这一机制不仅节省了宝贵的计算资源,也有效缩短了响应等待时间,提升用户体验。除了强大的语义匹配外,Semcache的另一个显著特点是其强大的兼容性和易用性。它支持多种主流语言模型提供商的API,包括OpenAI、Anthropic、Gemini等,使开发者无需对原有系统进行复杂改动,只需简单配置即可实现与Semcache的无缝对接。
其提供的HTTP代理模式支持一行代码替换,使得原有的请求流程通过Semcache进行拦截和处理,查询历史缓存并智能匹配,未命中的请求再自动转发至语言模型。此设计极大降低了集成门槛,为广大开发者切实节省了时间和人力成本。此外,Semcache还支持缓存策略的多样化管理,包括智能过期机制和缓存预加载策略,满足不同业务场景下对缓存有效性的灵活需求。持久化存储机制是Semcache提升应用价值的又一关键点。它能够将缓存数据长期保存,形成不断积累的知识库,实现对常见问题和高频请求的持续优化。对客服机器人、文档问答和用户反馈分析等应用场景尤为适用。
例如,在客服应用中,用户以多样化的自然语言表达询问诸如“运输费用多少?”、“运费是多少?”、“寄送费用怎么算?”等问题时,Semcache能迅速识别语义相似,直接调用缓存的标准答案,实现秒级响应并节约模型调用费用。在文档问答场景,Semcache则帮助企业快速响应关于产品说明书、操作指南的用户查询,无论用户询问“如何重置密码?”还是“修改登录凭证步骤?”均能动态匹配缓存,提升检索效率。随着企业对大规模语言模型调用的需求日益增长,Semcache还具备强大的监控与可观测能力,内置Prometheus指标和仪表盘,使用户可以实时跟踪缓存命中率、延迟表现与成本节省情况,便于优化缓存策略并提升整体系统性能。其支持社区版和企业版双重部署模式,用户既可以选择自建服务以满足自主管理需求,也可选用Semcache Cloud享受托管服务带来的便利和专属支持。总的来说,Semcache通过语义层面的创新缓存技术,为大型语言模型的高效利用及优化运营开辟了全新路径。它不仅提供了显著的性能提升与成本下降,更通过便利的生态兼容性和丰富的功能实现了商业应用的快速落地。
未来,随着语言模型在智能客服、智能问答、反馈分析等领域的深入应用,Semcache的价值将更加凸显,成为加速AI触达成效和降低研发运营门槛的重要利器。企业与开发者在拥抱这一工具的同时,也将收获更智能、高效和经济的语言模型解决方案体验。