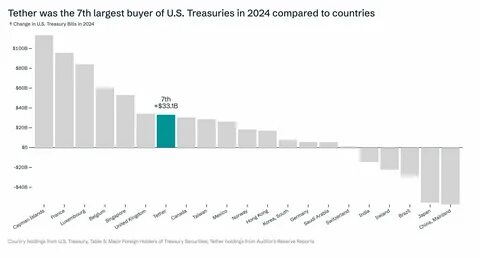
随着人工智能(AI)技术的发展,越来越多的人开始依赖AI来获取信息。然而,最近的分析结果显示,AI在处理与中国相关的问题时,其答案会因语言的不同而存在显著差异。这种现象引发了广泛的关注和讨论,本文将探讨导致这种差异的各种因素,包括语言的文化背景、训练数据集的选择以及算法的设计。 首先,语言作为一种文化现象,不仅仅是沟通的工具,更是文化、价值和思维方式的载体。当AI在不同语言环境中工作时,背后的文化背景和语言特征会直接影响其回答。例如,在中文环境中,AI可能会更加注重强调国家的稳定性和社会和谐,而在英文环境中,AI的回答可能更倾向于关注自由、民主等个体权利的问题。
这种文化塑造的差异是导致AI答案不一致的一个重要原因。 其次,训练数据集的选择对AI的表现起着至关重要的作用。AI系统的回答质量很大程度上取决于其训练时使用的数据。如果一个AI系统使用的是主要来自某种语言文化的数据集,那么它的回答很可能会受到这些数据的影响。例如,使用中文的数据集可能会使AI系统在回答涉及中国的问题时,倾向于保留更大的本土视角,而使用英文的数据集可能会导致回答更加国际化且受到西方观点的影响。 此外,算法本身的设计也会影响AI的回答。
不同的AI模型在处理信息时有不同的权重和偏见。如果一个模型被设计成优先考虑某种特定类型的信息(如科学数据、用户生成内容等),那么在处理某一主题时,它可能会偏向于某一特定文化或语言的观点,从而导致语言间回答的不一致性。 为了详细了解这一现象,研究者们进行了大量的实证分析。他们发现,当同一问题被用不同语言提问时,AI的回答常常展现出不同的重点和倾向。这种差异在涉及国内政策、社会问题及国际关系时尤为明显,对于学习、研究和商业活动都有较大的影响。 无论是学术研究、新闻报道,还是商业决策,意识到AI在语言上的偏见都至关重要。
当使用AI工具获取信息时,用户应当认可AI不仅仅是一个中立的工具,它的回答反映了背后复杂的训练和文化背景因素。因此,在使用AI时,需要从多种语言和文化背景出发,进行更全面的分析。 根据这些发现,很多用户开始关注多语言环境下AI的应用。无论是企业想要开发多语言客服机器人,还是个人希望获取更全面的信息,意识到这一问题都能帮助他们更好地理解AI的回答。提升多语言AI系统的表现,已经成为AI研究的一个重要方向。 最后,面对AI技术的迅速发展,尤其在国际化程度不断加深的背景下,如何提高AI在不同语言下的准确性和公平性,已经成为一个亟待解决的问题。
研究者们正在努力寻找解决方案,期望通过更均衡的数据集和智慧的算法设计,来减少AI回答中的语言差异。 综上所述,AI在处理与中国相关问题时,因语言不同而产生的答案差异是一个复杂而多层次的问题。它涉及到文化、数据和技术等多个方面。随着AI技术的不断进步,希望未来能够看到一个更全面和公正的AI系统,能够在多语言环境中提供一致且准确的信息。