在当今人工智能技术迅猛发展的时代,越来越多的产品团队依赖大型语言模型(LLM)来提升产品智能化水平。尤其是在产品评估阶段,部分团队尝试采用“LLM作为评判者”的思路,期望借助模型的自动化判断能力来快速筛查和改进产品缺陷。然而,事实证明,单纯依靠LLM作为评判工具并不能真正解决产品质量问题,甚至可能导致团队忽视对核心流程的改进和科学评估的重要性。产品的成败,根基不在于多一个自动化的评判模型,而在于完善合理的产品评估流程与数据驱动的迭代机制。理解这一点,是打造高质量AI产品的前提。产品评估不仅是一些静态的指标或简单的工具应用;它本质上是一种实践,是科学方法在产品研发中的具体体现。
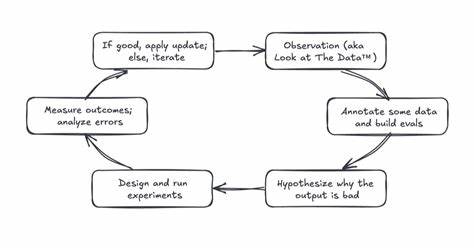
完整的产品评估过程包括观察数据、标注样本、提出假设、设计实验、测量结果和分析错误的连续循环。首先,观察数据意味着深入分析输入数据、AI的输出结果以及用户的交互行为,借此发现产品在哪些环节表现良好,在哪些地方存在明显缺陷。识别这些失败模式为后续改进奠定了基础。之后,团队需要对采样的数据进行标注,优先考虑有问题的输出,确保数据集中正反例均衡且覆盖多样化的情况,构建一个既代表成功也代表失败的样本库。这样,评估的精准度和针对性才得以保障。基于这些带标注的数据,产品研发团队能够形成针对具体失败案例的假设,比如某个文档检索组件未能提供足够相关的上下文,或是模型难以正确理解并执行复杂指令。
通过对错误输出、推理路径和检索结果的分析,团队能明确优先解决的问题和检验的假设。接下来便是设计和执行实验环节。实验可以涵盖修改提示词、优化检索模块、替换模型等多方面内容。重要的是,这些实验须明确预期结果,即哪些指标的变化可以验证假设的正确性。借助对照组或基准线条件,团队能科学地评判新改进的实际效果。测量实验结果并进行细致的错误分析,往往是最具挑战性的部分。
不同于表面的感觉或主观判断,团队必须量化改进是否真正带来了准确率的提升,是否减少了缺陷生成,或者在模型之间的对比中表现更佳。没有精确的数据支持,任何改动都难以促进有效改进。当实验验证假设成功时,研发团队将相关改动部署上线;反之,则需要重新审视错误原因,优化假设并继续迭代。正是以这种持续循环的方式,产品评估形成了推动产品迭代的强大数据飞轮,直接促进缺陷减速和用户信任的增加。这种严谨的科学方法驱动的产品开发模式,也被称为评估驱动开发(Eval-Driven Development,EDD)。它的理念与软件领域的测试驱动开发类似,即先设计指标和测试标准,再进行功能实现,确保开发目标清晰且可验证。
机器学习团队几十年来一直遵循类似的验证和测试流程,只是命名不同。通过EDD,团队从设计初期就明确成功标准,基于评估持续跟踪每一次改动的实际影响。这样的机制极大减少了直觉式判断和盲目迭代,强化了开发过程中的科学严谨性和效果反馈。即便引入自动化评估工具,例如LLM作为评判者,也不能取代人类监督。自动化评估固然能扩大监控规模,提升检测效率,但它无法脱离完善的人工监控和反馈体系独立发挥作用。只有在团队定期采样输出、精准标注质量与缺陷、以及系统分析用户反馈的基础上,自动化评估才能持续校准并精进,与人类评判保持高度一致性。
实践中,对采样数据的持续标注和对用户交互隐式以及显式反馈的捕获,是保障评估体系健康运行的关键。人工成本虽高,却不可或缺。且自动化评估工具并非完美,同样存在错判和偏差,但通过持续提升标注质量和反馈量,往往能不断优化这些工具的表现。组织层面的纪律和文化建设尤为重要,必须保持标注-反馈-自动化评估的完整闭环,否则即使配置最先进的技术也难以真正提高产品质量。综上所述,依赖LLM作为评判者仅是评估手段的一部分,核心仍然是高质量的流程建设和数据驱动的持续迭代改进。建立基于科学方法的评估循环,积极将评价标准纳入产品开发全周期,并确保人机结合的严谨监督与反馈体系,才是构建卓越AI产品的根本之道。
那些希望借助“魔法”一次性解决评估难题的团队,往往忽视了产品研发的本质:那就是勤奋的工作和精准的流程管理。未来的AI产品能够脱颖而出,不在于引入多少自动评判的“黑科技”,而在于团队多版本迭代、数据驱动决策和科学实验的扎实积累。只有持续赋能评估流程,方法论落地生根,AI产品才能真正赢得广大用户的信任与青睐。









