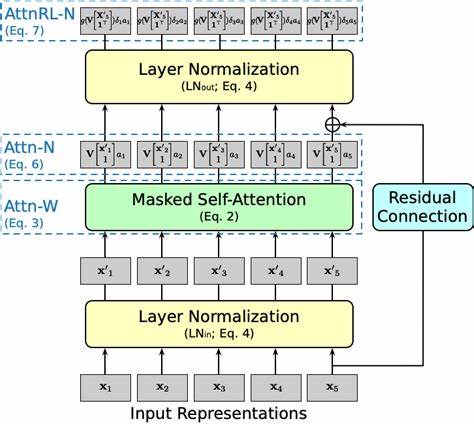
随着深度学习技术的快速发展,变换器模型因其在自然语言处理领域的卓越表现而备受关注。自注意力机制作为变换器的核心组成部分,通过捕捉序列中各元素间的依赖关系,实现了对上下文的深度理解。然而,自注意力的计算复杂度随序列长度呈二次增长,极大限制了其在长序列处理中的效率和适用性。为解决这一瓶颈,研究者们提出了多种改进方案,其中求和聚合作为一种简洁高效的替代机制,展现了实现线性计算复杂度的巨大潜力。求和聚合的核心思想在于用简单的求和操作替换复杂的注意力权重计算。具体来说,每个输入标记首先通过一个线性变换以及非线性激活函数,结合位置编码进行调制,以保留位置信息和语义特征。
随后,将所有经过变换后的标记向量进行直接相加,形成整体的聚合表示。这种方式避免了自注意力中计算所有标记对之间权重的昂贵操作,计算成本仅随着序列长度线性增加,从而极大提升了模型的效率。求和聚合在文档分类任务中表现出令人惊讶的竞争力。在单独测试时,求和机制的性能接近传统的全自注意力架构,显示其有能力捕捉足够的语义信息用于分类决策。虽然在纯自回归语言建模中,求和聚合的表现略逊一筹,但结合混合设计,即在网络中层采用求和聚合而在输出层保留单一的注意力机制,使得整体性能达到甚至超过了全自注意力模型。这种设计不仅兼顾了模型性能,也保持了大部分计算过程的线性复杂度,显著降低了训练和推理时间成本。
在多模态回归任务中,求和聚合展现出其独特优势。通过共享的汇聚通道,不同类型的输入数据能够有效融合,促进模型在多样化输入环境下的泛化能力。这种共通的汇总特征为跨模态理解和生成提供了新的可能,显示了求和聚合在多模态学习领域的广阔前景。求和聚合机制提出了关于信息瓶颈和抽象表达的新视角。传统自注意力通过权重分配灵活调整信息流,而求和聚合则通过固定的求和操作限制信息路径,迫使模型学习更加紧凑和抽象的表示。这种瓶颈机制可能有助于提高模型的泛化能力和鲁棒性,值得进一步的理论研究和实践验证。
尽管求和聚合尚在发展初期,预印本阶段的研究成果已指出其作为实用的变换器优化方案的潜力。未来,结合更多混合结构和优化策略,求和聚合有望成为解决长序列效率难题的重要路径。此外,对于实际应用场景如实时语音识别、长文档处理和多模态交互等,求和聚合的线性复杂度优势尤为突出。综上所述,求和聚合为变换器模型提供了一条简洁且高效的替代道路,缓解了自注意力机制中复杂计算带来的瓶颈问题。它不仅提升了计算效率,还保持或超越了部分任务的性能表现,推动了序列模型向更大规模与多样化方向发展。伴随着学术界和工业界的持续关注和探索,求和聚合有望成为未来智能系统设计中的重要技术基石,引领深度学习与人工智能迈向新的高度。
。